














![OPERACIONES
2 5 1 6 5 5 4 1
Para ingresar estos valores en una sesión de
R, asignándolos al objeto escribimos pepe
> pepe <- c(2,5,1,6,5,5,4,1)
y si escribimos
> pepe
y oprimimos enter, aparecerá lo siguiente
[1] 2 5 1 6 5 5 4 1
> t<-c(1,1.2,1.3,1,1.2,1.3,1.4)
> g<-c(5,4.5,5.5,4.7,5.1,4.4,4.8)
variable
Toma el valor
de](https://image.slidesharecdn.com/descriptivo-150808040020-lva1-app6892/85/Descriptivo-17-320.jpg)



![Cualitativo
u<-c("lima","tacna","lima","tacna","piura","tacna","piura","lima","lima","piura")
length(u)
[1] 10
> tabla1<- table(u)
> tabla1
u
lima piura tacna
4 3 3
> table(u)
u
lima piura tacna
4 3 3](https://image.slidesharecdn.com/descriptivo-150808040020-lva1-app6892/85/Descriptivo-21-320.jpg)













![DESCRIPTIVOS
mean(x)
median(x)
sd(x)
var(x)
Summary(x)
> mean(t)
[1] 1.2
> median(t)
[1] 1.2
> sd(t)
[1] 0.1527525
> var(t)
[1] 0.02333333
> summary(t)
Min. 1st Qu. Median Mean 3rd Qu. Max.
1.0 1.1 1.2 1.2 1.3 1.4
> t<-c(1,1.2,1.3,1,1.2,1.3,1.4)](https://image.slidesharecdn.com/descriptivo-150808040020-lva1-app6892/85/Descriptivo-35-320.jpg)
![length(g)
[1] 10
summary(g)
Min. 1st Qu. Median Mean 3rd Qu. Max.
12.0 23.5 26.5 28.0 34.0 45.0](https://image.slidesharecdn.com/descriptivo-150808040020-lva1-app6892/85/Descriptivo-36-320.jpg)


![Con base de datos
memoria=read.csv("G:/memoria.csv")
mean(memoria[,15])
[1] 71.52174
memoria=read.csv("C:/Users/Advance/Deskto
p/memoria.csv")
sd(memoria[,15])
[1] 9.711518
39](https://image.slidesharecdn.com/descriptivo-150808040020-lva1-app6892/85/Descriptivo-39-320.jpg)



![CORRELACIONES
> t<-c(1,1.2,1.3,1,1.2,1.3,1.4)
> g<-c(5,4.5,5.5,4.7,5.1,4.4,4.8)
> cor(t,g)
[1] 0.02886751
> cor.test(t,g)
Pearson's product-moment correlation
data: t and g
t = 0.0646, df = 5, p-value = 0.951
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.7402836 0.7652891
sample estimates:
cor
0.02886751](https://image.slidesharecdn.com/descriptivo-150808040020-lva1-app6892/85/Descriptivo-43-320.jpg)










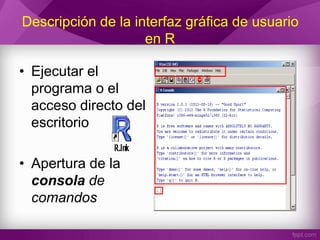
Este documento contiene información sobre estadística descriptiva y análisis exploratorio de datos. Explica conceptos como medidas de tendencia central, medidas de dispersión, distribución de frecuencias, representaciones gráficas, y estadísticos de asociación. También describe cómo obtener y usar el software R para realizar análisis estadísticos e incluye ejemplos de código R.








































































































