Descargar para leer sin conexión





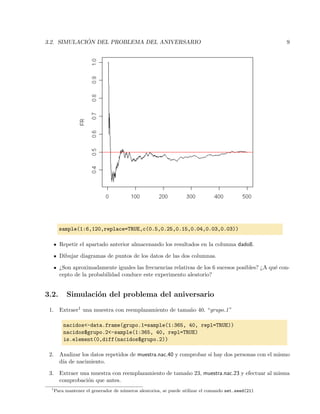
![6 TEMA 3. VARIABLES ALEATORIAS
1 2 3 4 5 6
0510152025
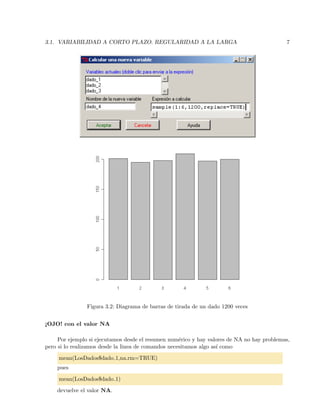
Figura 3.1: Diagrama de barras de tirada de un dado 120 veces
3.1.2. Variabilidad a largo plazo:
Simular 1200 lanzamientos de un dado regular (no trucado), almacenando los resultados de
los lanzamientos en la columna 4 (”dado_4”).
El entorno gr´afico nos impide obtener los 1200 datos, ¿como lo hacemos? Se puede entrar en
el editor y avanzar p´aginas hasta la fila de datos 1200, e introducir en esta casilla un NA.
Otra posibilidad desde la l´ınea de comandos, es escribir
LosDados[1200,] <- c(NA,NA,NA)
y a continuaci´on simular el lanzamiento del cuarto dado.
Y por supuesto lo m´as c´omodo ser´ıa abrir un nuevo data.frame
Repetir el apartado anterior almacenando los resultados en la columna 5 y 6 (”dado_5”) y
(”dado_6”).
Dibujar diagramas de barras de los datos de las dos columnas.
>barplot(table(LosDados$dado_4))
Calcular las frecuencias relativas de los 6 sucesos posibles. ¿Son estas frecuencias relativas
iguales a 1
6 ?](https://image.slidesharecdn.com/manualr2-170904185457/85/Manual-r-2-6-320.jpg)
![8 TEMA 3. VARIABLES ALEATORIAS
Otra posibilidad para evitar los valores omitidos y poder calcular con datos que incluyen un
NA es,
x[!is.na(x)]
ya que, este comando elimina del vector x todos aquellos el mentos que sean NA o NaN. La
funci´on which(is.nan(x)) nos devolver´a las posiciones de los elementos de x que toman el valor
NaN.
3.1.3. Concepto frecuentista de la probabilidad
La concepci´on frecuentista interpreta que la probabilidad de un suceso es el l´ımite de la
frecuencia relativa de dicho suceso cuando el n´umero de veces que se repite el experimento asociado
tiende a infinito.
Por ejemplo, que la probabilidad de sacar cruz al tirar una moneda es 0,5 significa que, en una
sucesi´on de tiradas, la frecuencia relativa de las cruces obtenidas se ir aproximando paulatinamente
a 0,5 seg´un avanza la sucesi´on.
Generamos un vector que represente la sucesi´on de tiradas; suponiendo n = 500 tiradas.
dadoplot <- data.frame(caras=sample(c(0, 1), 500,replace=TRUE))
dadoplot$FA <- with(dadoplot, cumsum(caras))
plot (FR, type=’l’)
abline (0.5, 0, col=’red’)
Calculamos las frecuencias relativas de las cruces en cada tirada.
Representamos la secuencia de frecuencias relativas acumuladas.
Podemos a˜nadir la as´ıntota, a la altura del valor te´orico de la probabilidad p = 0,5
3.1.4. ¿Es siempre admisible el concepto cl´asico de probabilidad?
Simular 120 lanzamientos de un dado en cuyo interior se han introducido asim´etricamente bolas
de acero, de forma que P(1) = 0,5; P(2) = 0,25; P(3) = 0,15; P(4) = 0,04 y P(5) = P(6) = 0,03.
Almacenar los resultados de los lanzamientos en la variable dado7.](https://image.slidesharecdn.com/manualr2-170904185457/85/Manual-r-2-8-320.jpg)





![18 TEMA 5. BONDAD DE AJUSTE
>chisq.test(frec,p=prob)
Chi-squared test for given probabilities
data: frec X-squared = 15.75, df = 5, p-value = 0.007595
5.1.2. Bombardeo de Londres
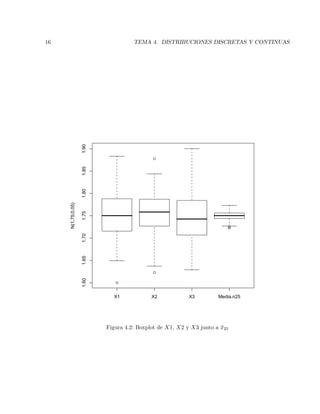
Durante la Segunda Guerra Mundial se dividi´o el mapa de Londres en cuadr´ıculas de 1/4 km
y se cont´o el n´umero de bombas ca´ıdas en cada cuadr´ıcula durante un bombardeo alem´an. Los
resultados fueron:
x: Impactos en cuadr´ıcula 0 1 2 3 4 5
Oi: frecuencia 229 211 93 35 7 1
Se quiere contrastar la hip´otesis de que los datos siguen una distribuci´on de Poisson. Se pide:
1. Dise˜nar las columnas adecuadas que registren las frecuencias observadas y las esperadas.
lambda<-sum(fre*impac)/sum(fre)
Calculamos las probabilidades de Poisson con
londres$prob <- with(londres, round(dpois(0:5, lambda=0.9288194),4))
2. Calcular el estad´ıstico del contraste χ2.
>chisq.test(londres$fre.a[1:5],p=londres$prob[1:5])
data: londres$fre.a[1:5] X-squared = 1.0118, df = 4, p-value =0.908
3. Hallar el cuantil 0,95 de la distribuci´on χ2
g.l. y decidir si se acepta que los datos de la muestra
se ajustan a la distribuci´on te´orica.](https://image.slidesharecdn.com/manualr2-170904185457/85/Manual-r-2-18-320.jpg)



![22 TEMA 7. INTERVALOS DE CONFIANZA Y CONTRASTES DE HIP ´OTESIS
t.test(Pulso$Peso, alternative=’two.sided’, mu=0.0, conf.level=.95)
One Sample t-test
data: Pulso$Peso t = 58.6473, df = 91, p-value <2.2e-16
alternative hypothesis: true mean is not equal to 0 95 percent confidence interval:
63.66709 68.13108
sample estimates: mean of x 65.89909
help(t.test)
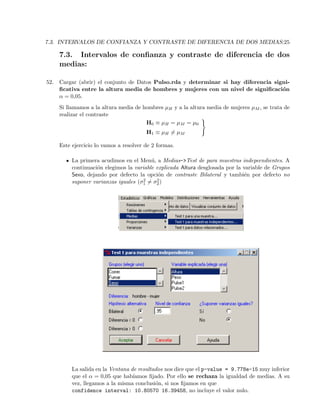
b) Calcular el intervalo de confianza para el peso medio de las mujeres con
α = 0,05.
En este caso, si se quiere trabajar con el data.frame habr´ıa que crear una columna con
los pesos de las mujeres dejando NA para los pesos de los hombres. A continuaci´on se
proceder´ıa como en el apartado anterior.
Pero la forma m´as sencilla es recuperar el comando de t.test del apartado anterior e
indicarle la variable adecuada.
t.test(Peso[Sexo==’mujer’], alternative=’two.sided’, mu=0.0,
conf.level=.95)
intervalo 54.12-58.29
c) Estudios recientes afirman que la altura media de las mujeres de esta poblaci´on
es µ = 167 cm. A la vista de estos datos, ¿podemos aceptar dicha hip´otesis?
Como en el caso anterior para el intervalo, ahora indicamos el valor de µ a contrastar
mu=167
t.test(Altura[Sexo==’mujer’], alternative=’two.sided’,
mu=167, conf.level=.95)
p-value 0.4273
Se observa que el p-valor obtenido es superior al nivel de significaci´on fijado en α = 0,05,
luego aceptar´ıamos la hip´otesis.
d) Calcular el intervalo de confianza para el Pulso1 medio de las mujeres que no fuman.
t.test(Pulse1[Sexo==’mujer’ & Fumar==’no’],alternative=’two.sided’,
mu=0.0, conf.level=.95)
(70,36 − 78,83)
e) Calcular el intervalo de confianza para la media del incremento del pulso (Pulso2-Pulso1)
para los individuos que corrieron.
t.test(increpulso[Correr==’corrio’], alternative=’two.sided’,
mu=0.0, conf.level=.95)
(13,74 − 24,08)](https://image.slidesharecdn.com/manualr2-170904185457/85/Manual-r-2-22-320.jpg)


![26 TEMA 7. INTERVALOS DE CONFIANZA Y CONTRASTES DE HIP ´OTESIS
> t.test(Altura~Sexo, alternative=’two.sided’, conf.level=.95,
var.equal=FALSE, data=Pulsaciones)
Welch Two Sample t-test
data: Altura by Sexo t = 9.7007, df = 72.514, p-value = 9.778e-15
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
10.80570 16.39458
sample estimates: mean in group hombre mean in group mujer
179.7161 166.1160
El m´etodo anterior con men´us requiere tener los valores de las dos variables en una
misma columna y a su vez desglosada con otra columna que hace de factor. La segunda
forma es m´as vers´atil.
A partir del comando t.test de arriba bastar´ıa escribir:
t.test(Altura[Sexo==’hombre’],Altura[Sexo==’mujer’],
var.equal=FALSE, alternative=’two.sided’, conf.level=.95,
Teniendo en cuenta que la selecci´on de las variables puede ser m´as complicado que las opciones
que ofrece el Men´u de Rcommander, la segunda forma es m´as flexible que la primera.](https://image.slidesharecdn.com/manualr2-170904185457/85/Manual-r-2-26-320.jpg)



Este documento presenta una introducción a las variables aleatorias y las distribuciones de probabilidad discretas y continuas más comunes utilizando el lenguaje R. En la sección 3, se explica la variabilidad a corto y largo plazo de las variables aleatorias y se simulan experimentos aleatorios como el problema del aniversario y los dados de Galileo. La sección 4 describe las distribuciones binomial, de Poisson y normal, y muestra cómo calcular probabilidades y generar muestras aleatorias para cada una en R. Finalmente, la sección 5 presenta ejemplos de







































































