Descargado 153 veces




























El Assistant es una herramienta interactiva que guía al usuario a través de los pasos necesarios para realizar un análisis estadístico. Se accede a él desde el menú Calc/Assistant. Constants: Permite definir constantes que se pueden utilizar en cálculos posteriores. Por ejemplo, definir π como 3.14159. Transform: Transform permite realizar transformaciones de datos como logaritmos, raíces, potencias, etc. También se pueden crear nuevas variables como suma, resta, multiplicación o división de otras variables exist
Esta sección presenta la Escuela Superior de Ingenieros de San Sebastián y el propósito de la guía sobre Minitab 14 para métodos estadísticos.
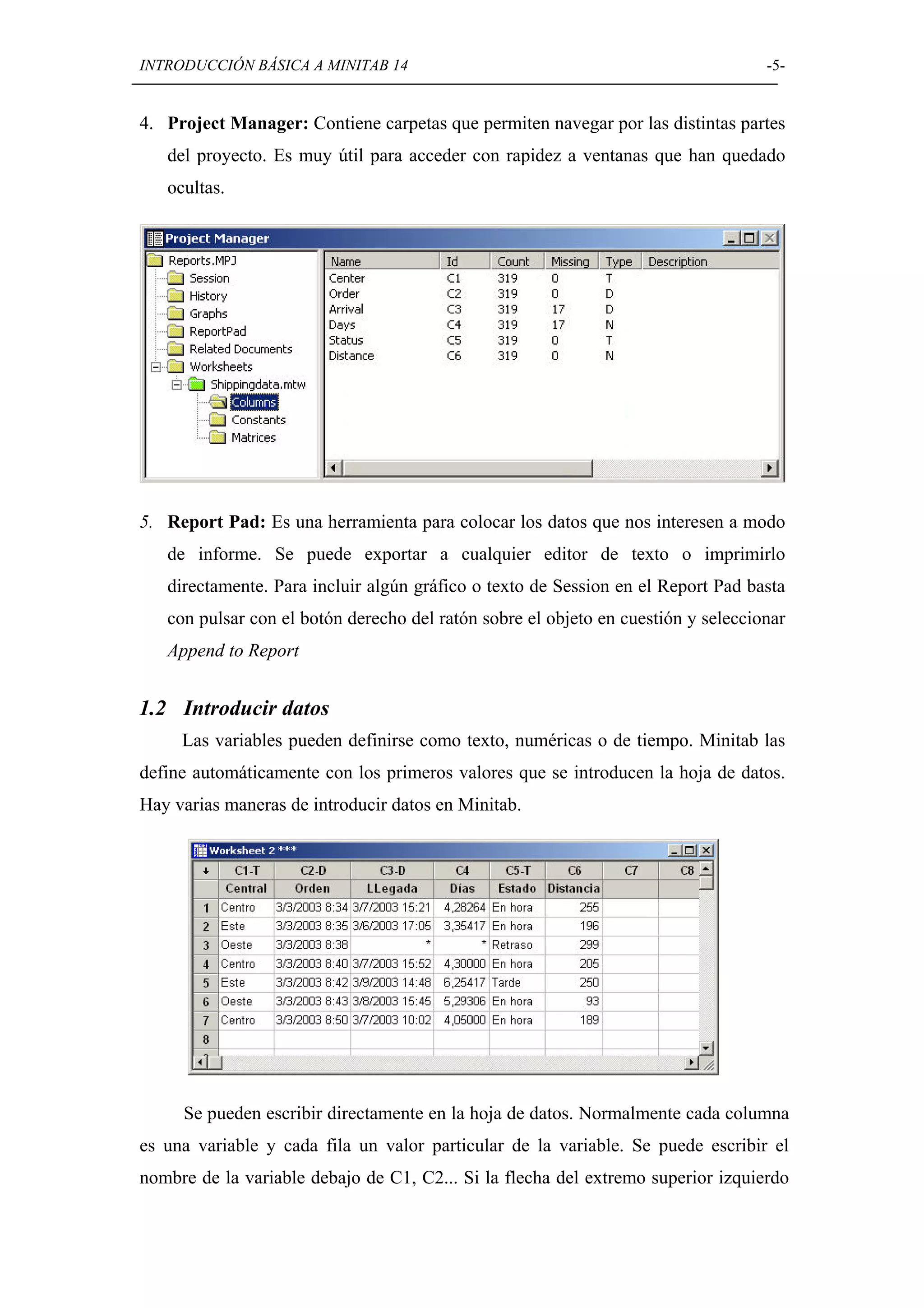
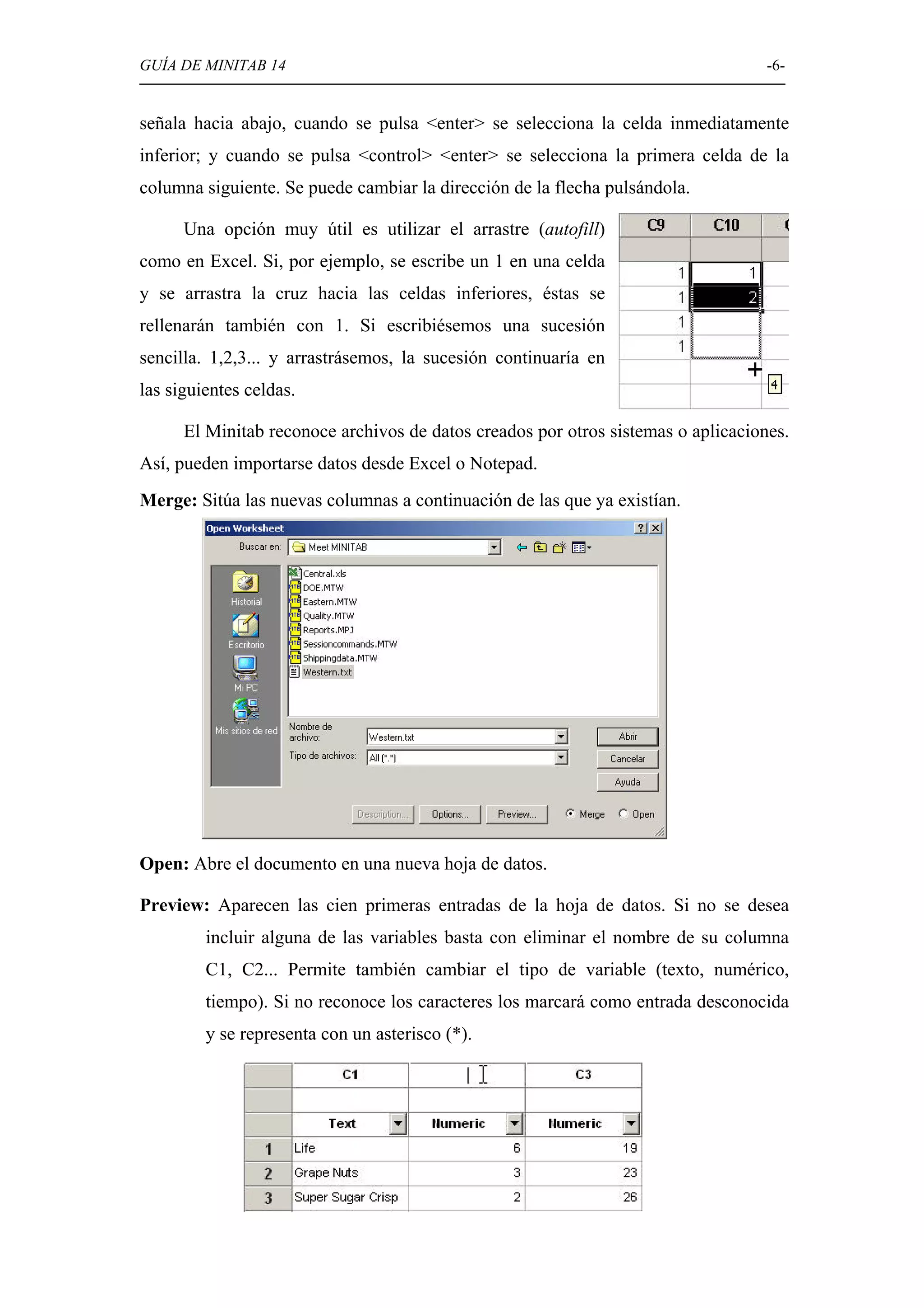
Introducción a la interfaz de Minitab, incluyendo ventanas, menús, y cómo introducir y guardar datos.
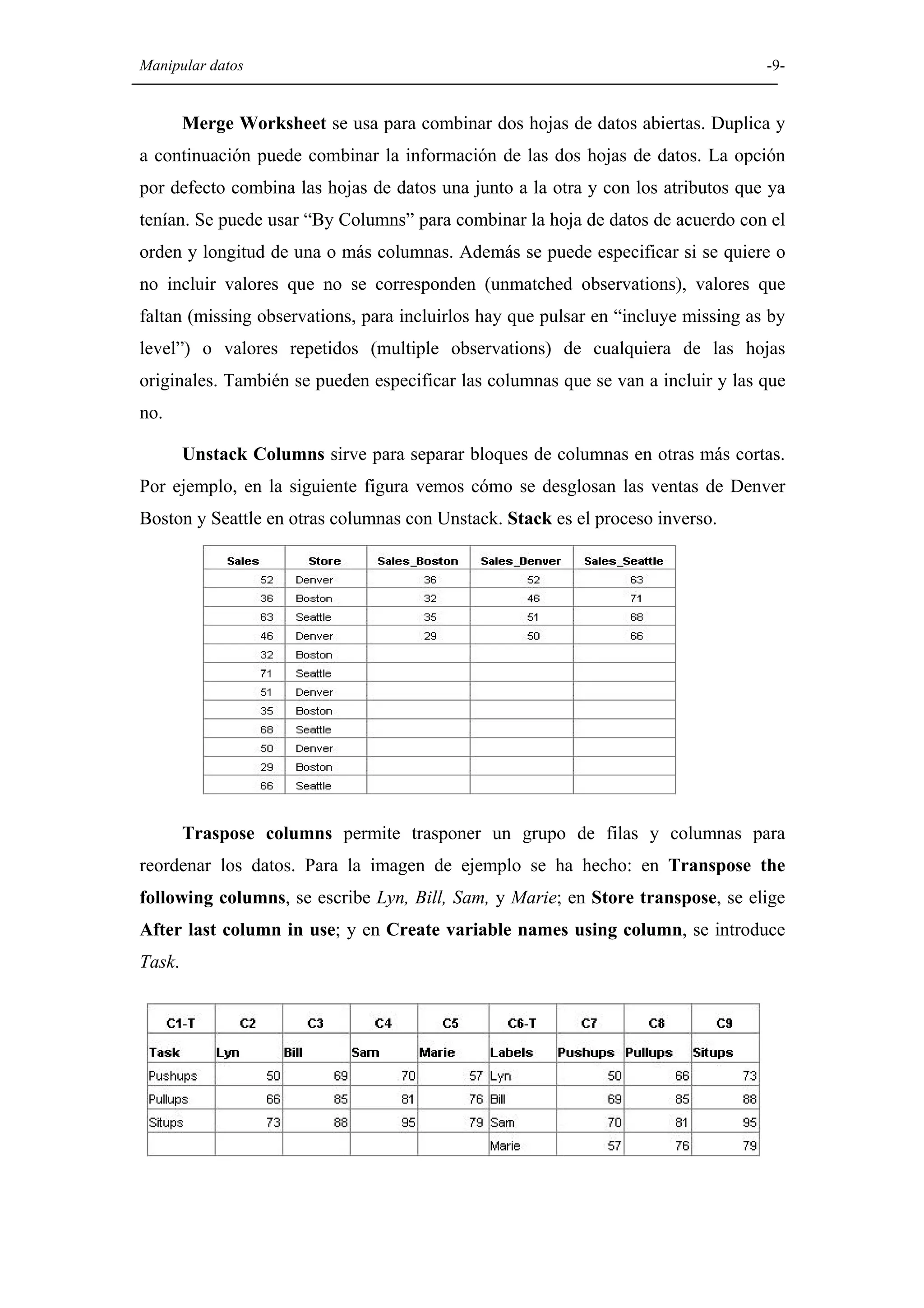
Sección sobre cómo manipular datos en Minitab, incluyendo funciones para ordenar, clasificar y transponer columnas.
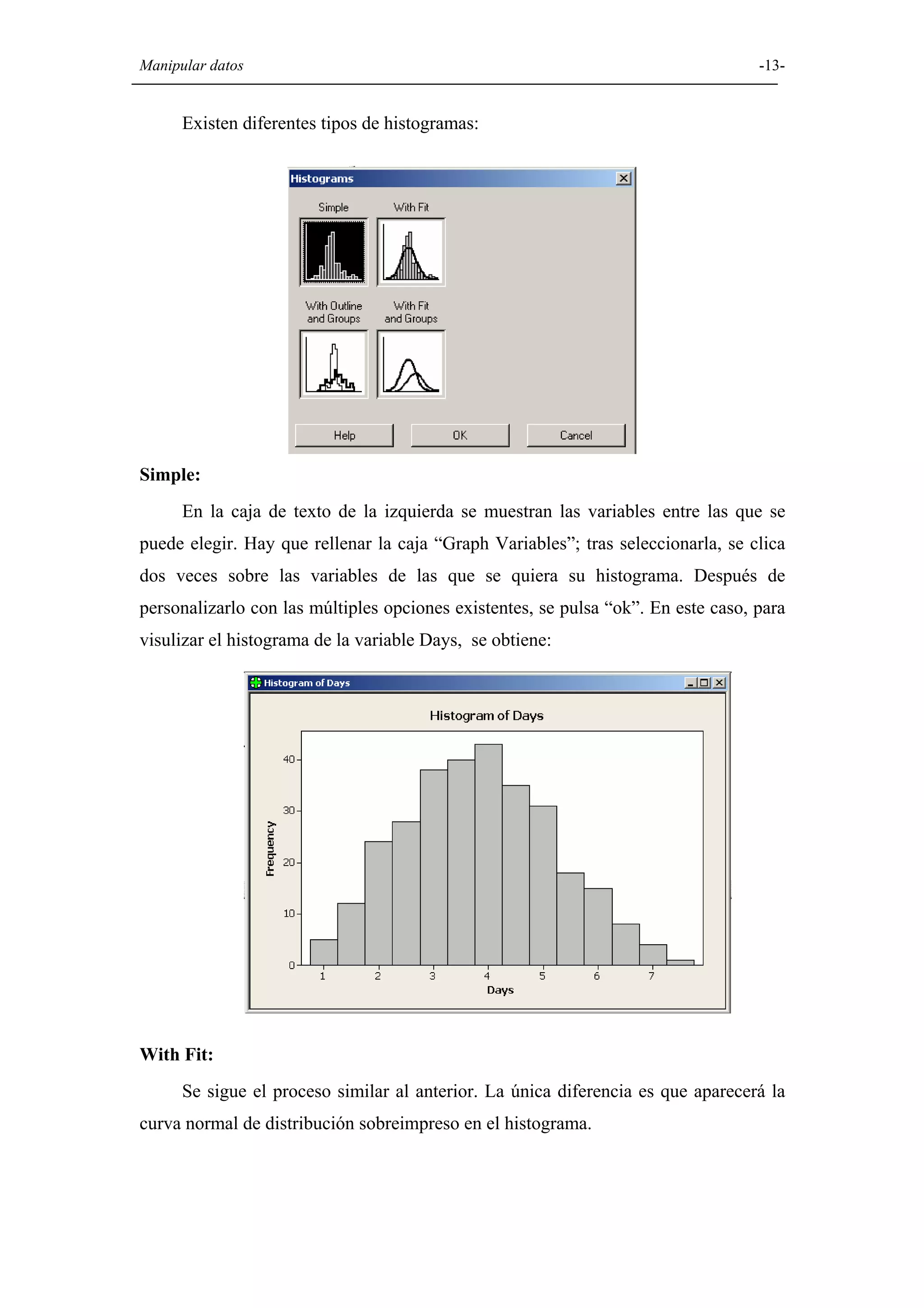
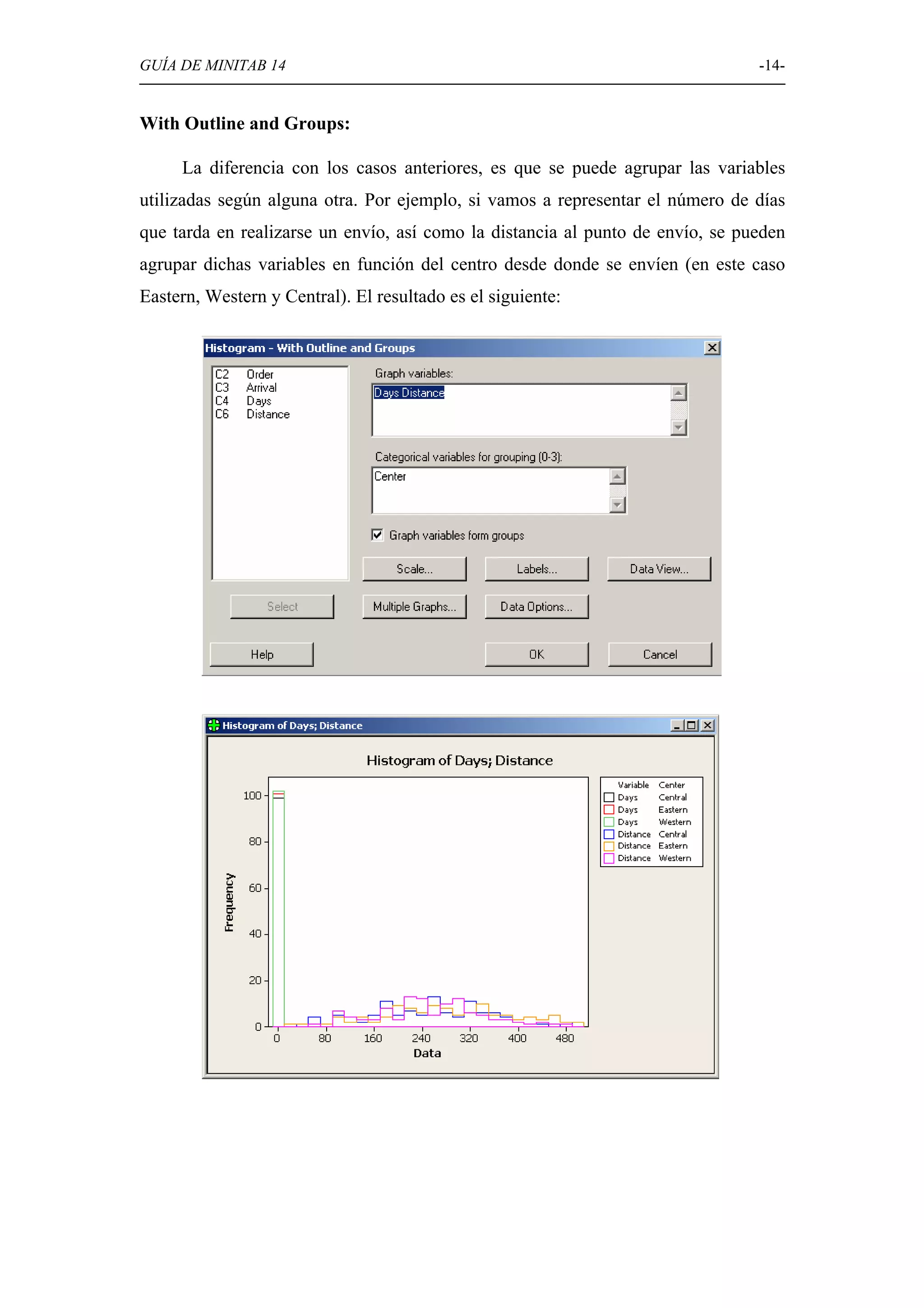
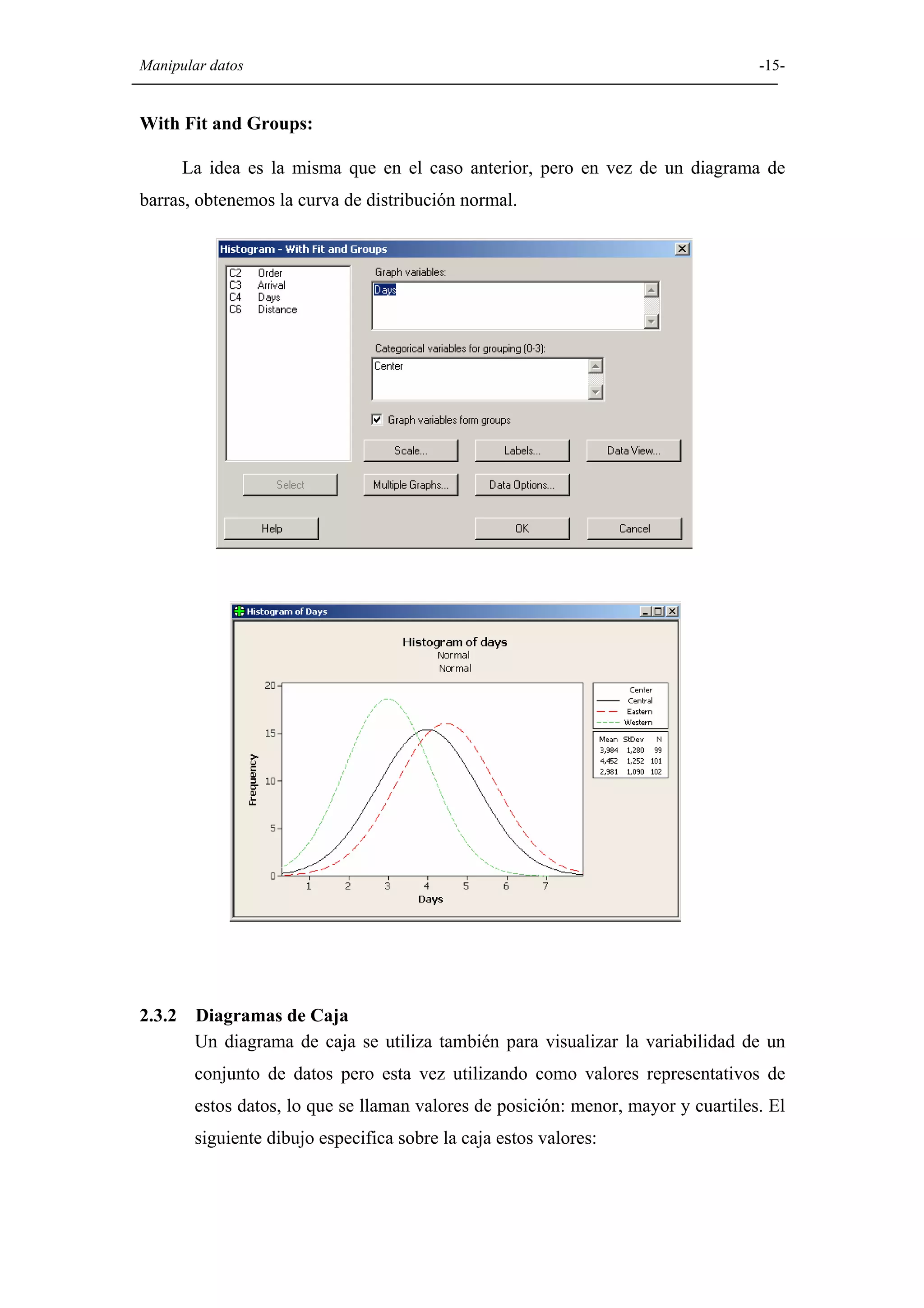
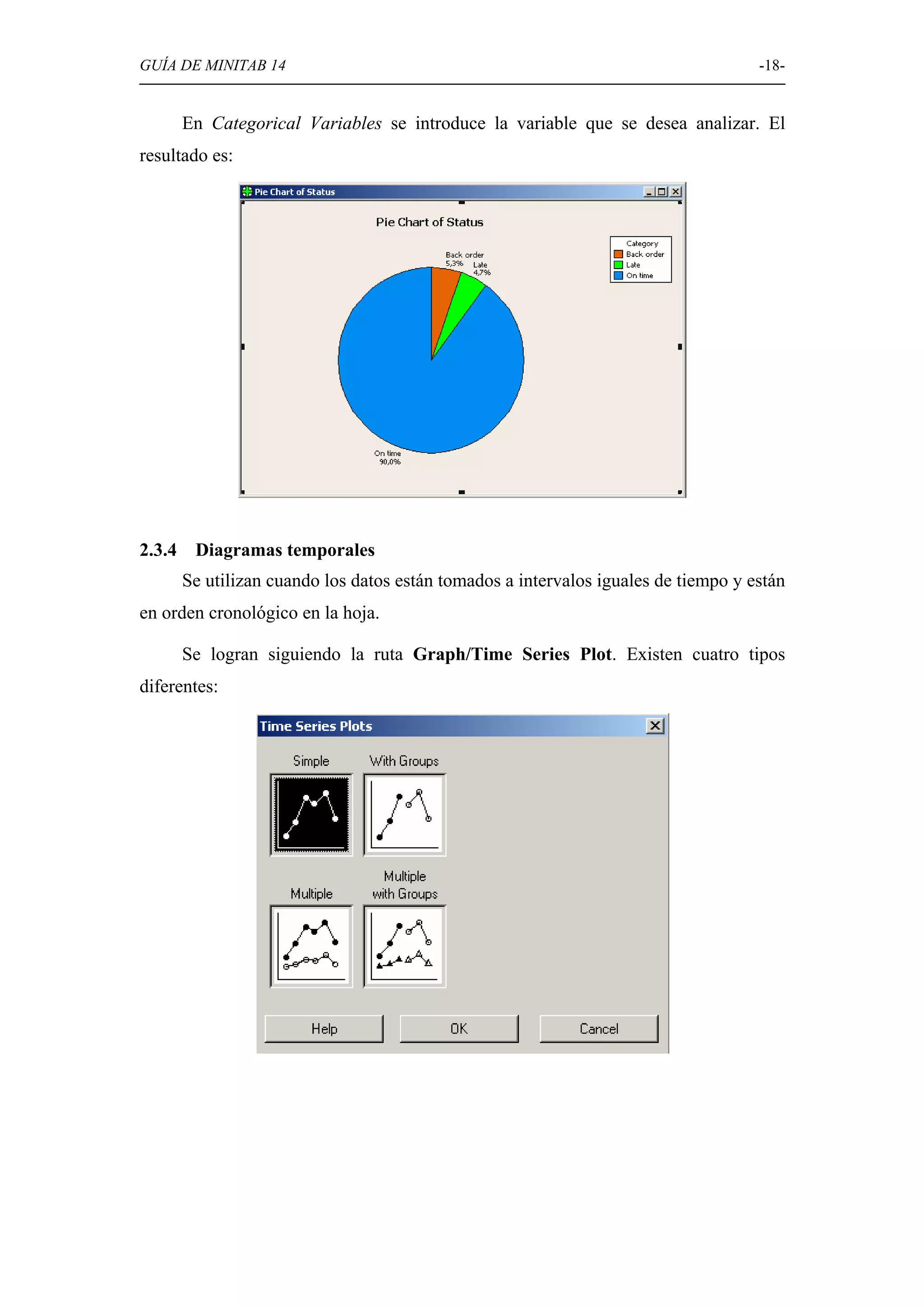
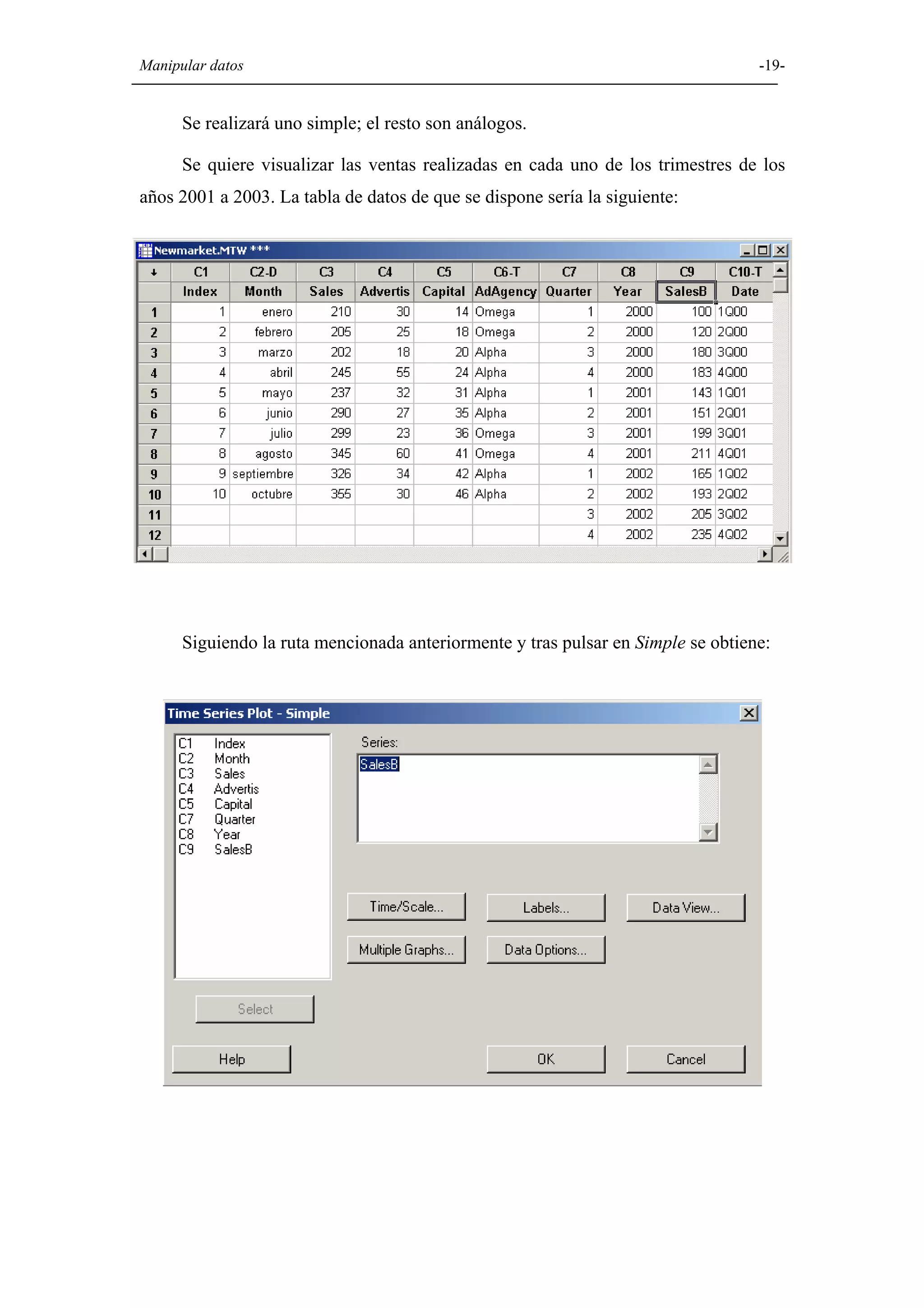
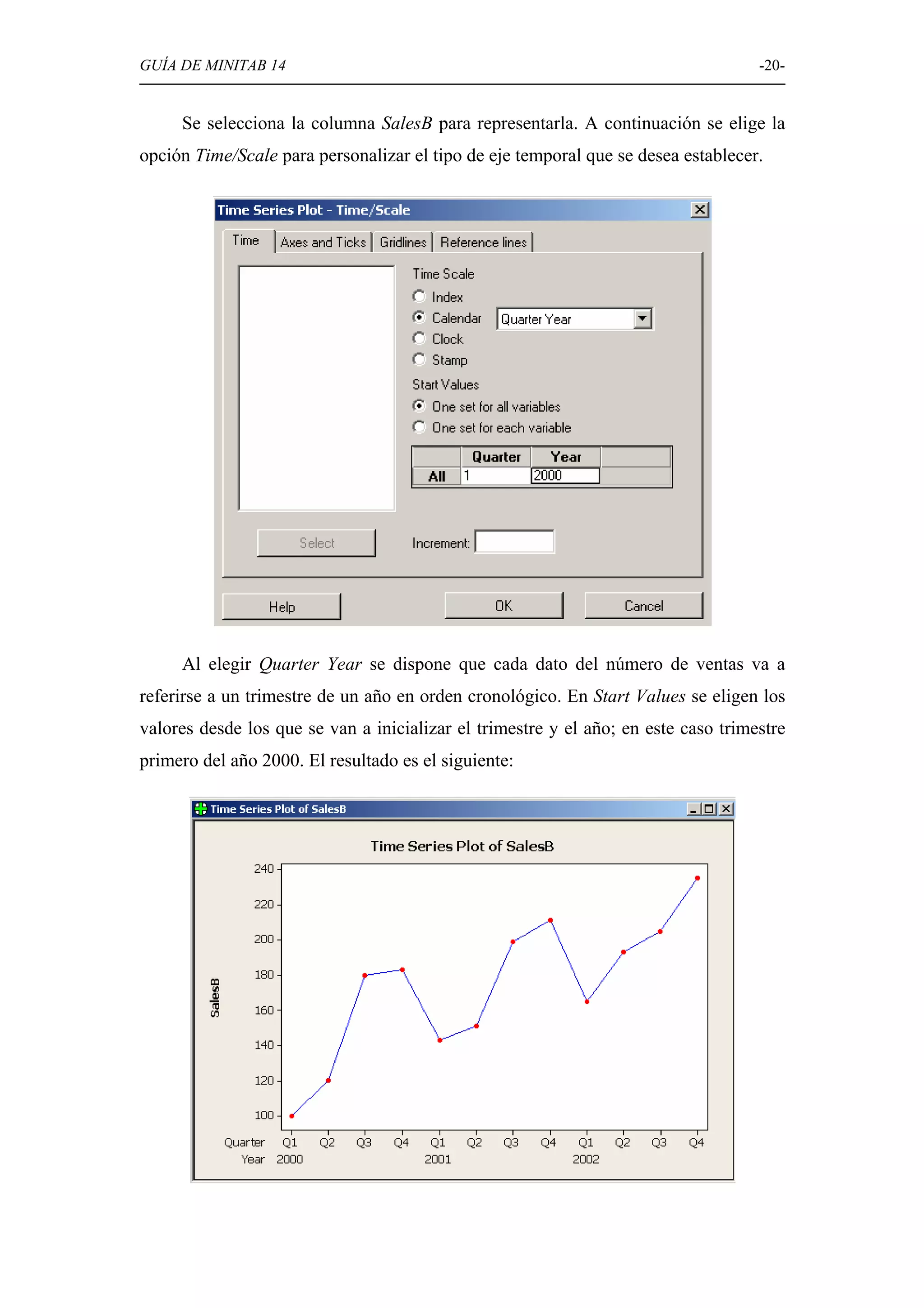
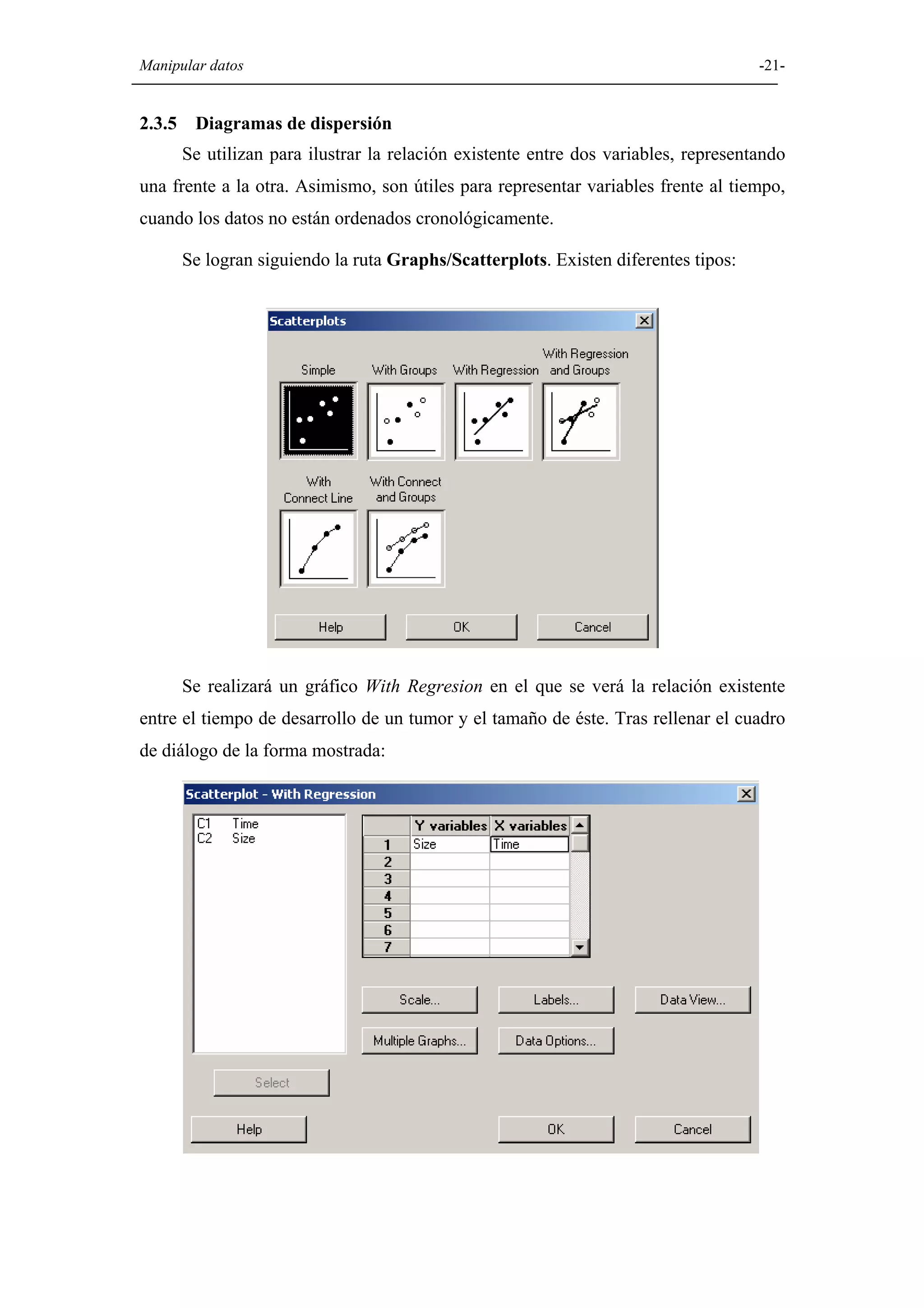
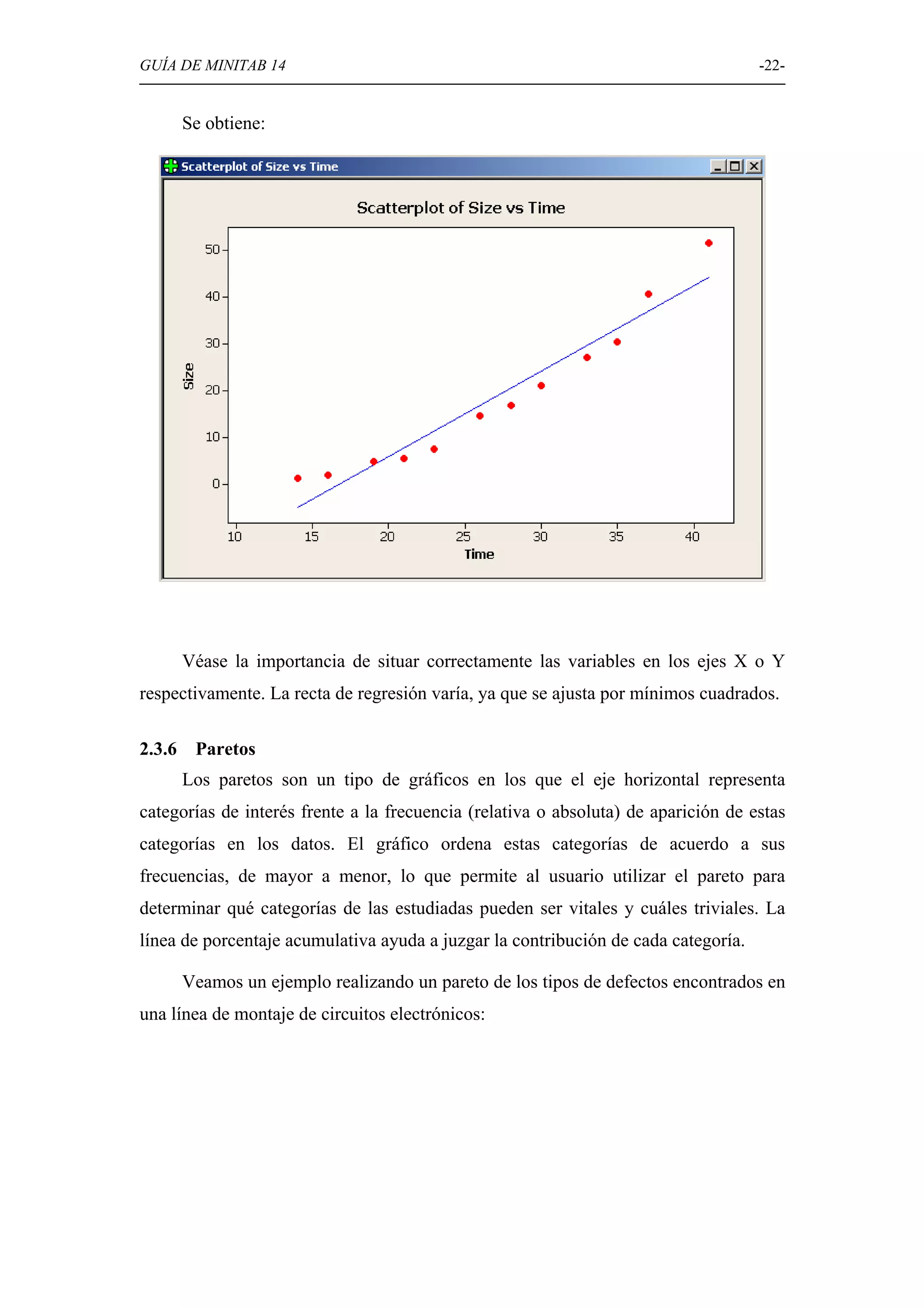
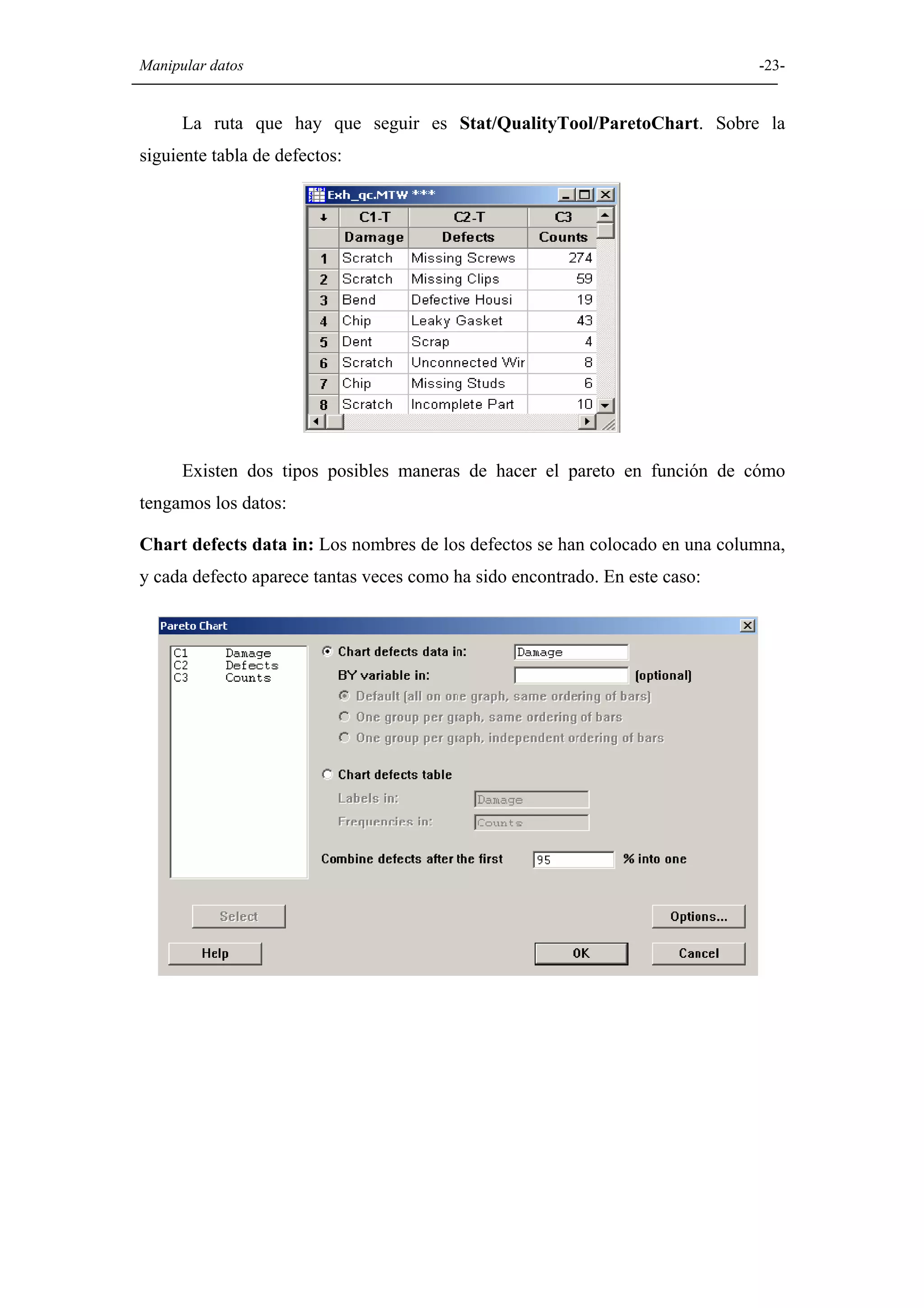
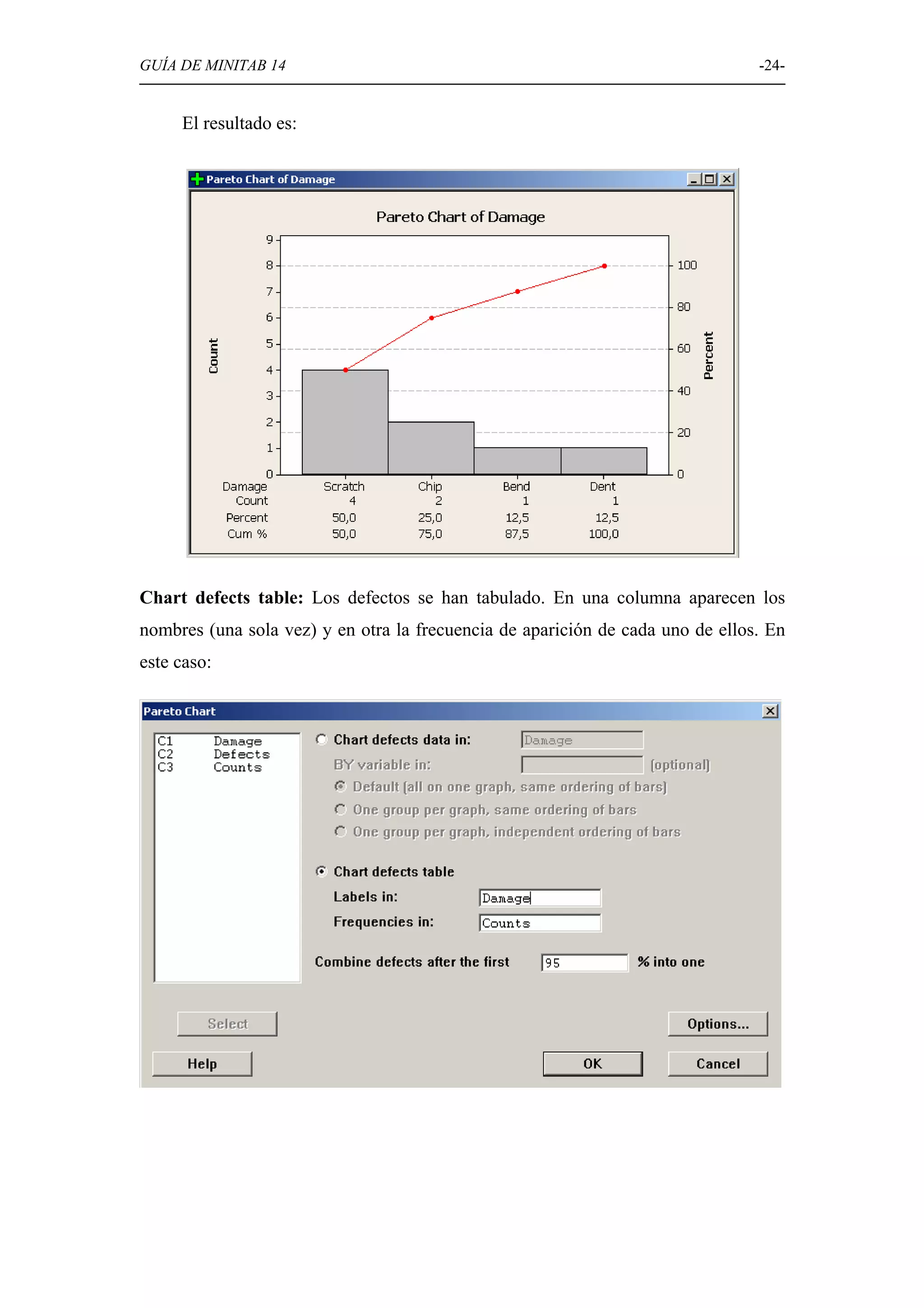
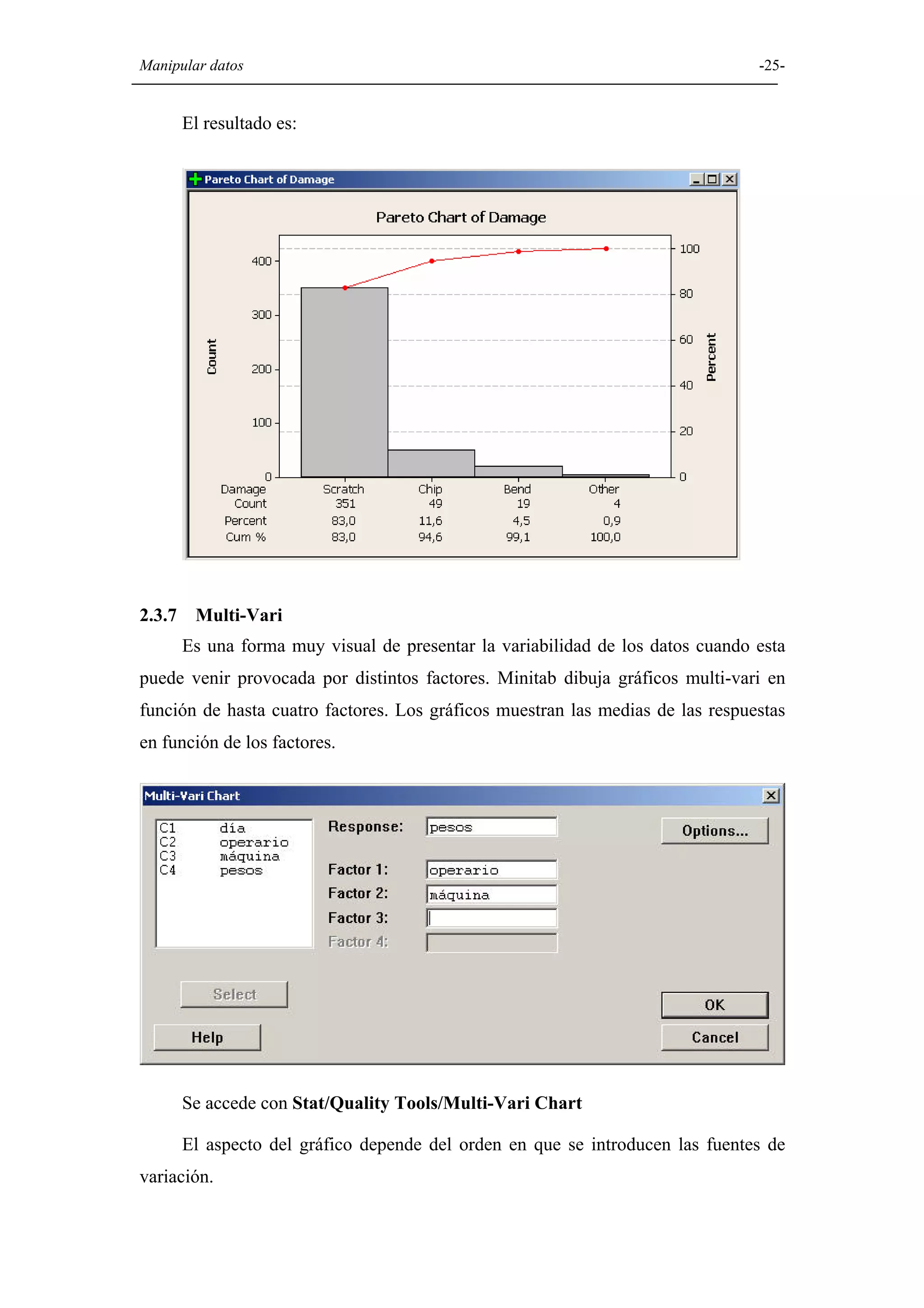
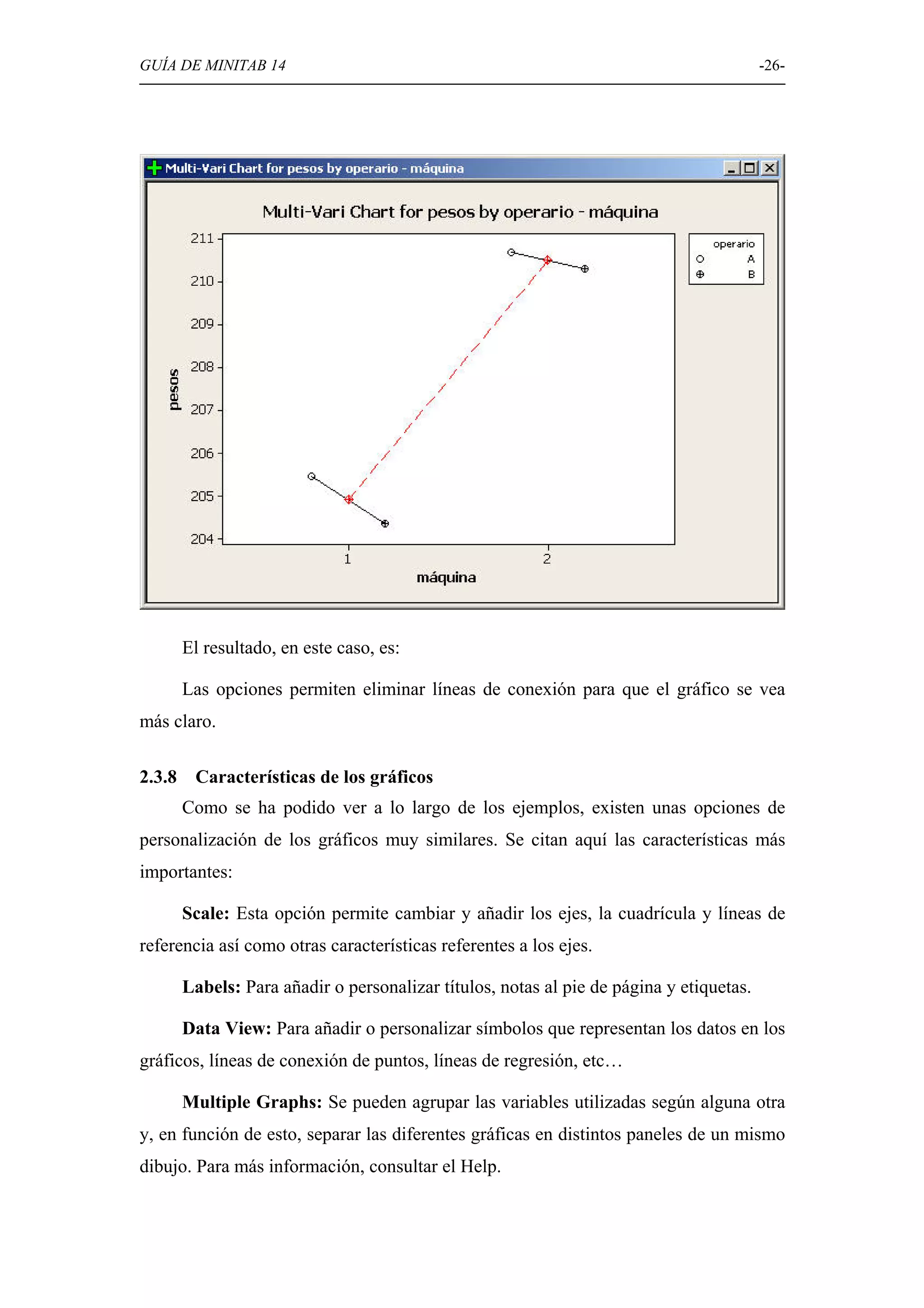
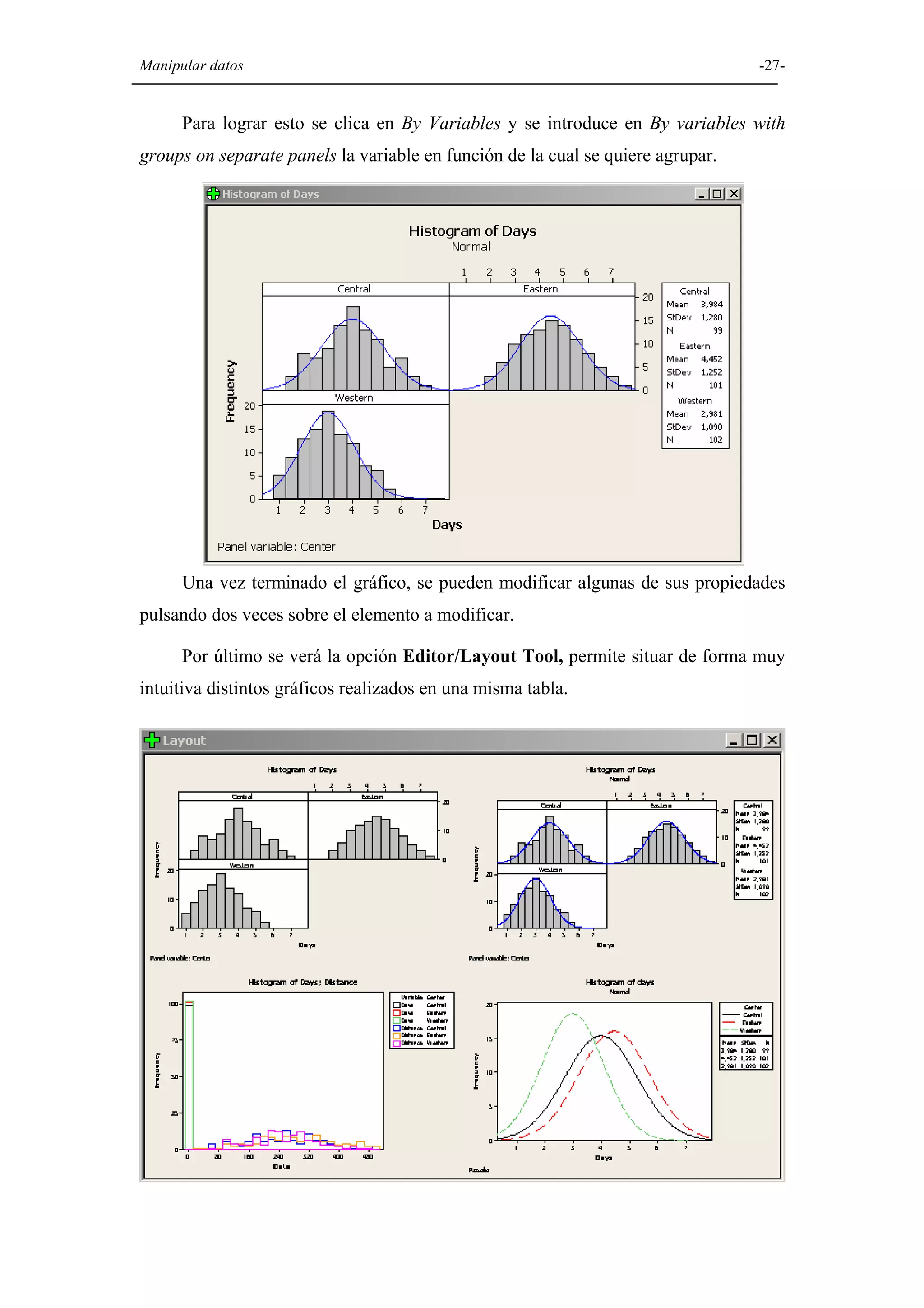
Explicación de diversas opciones gráficas en Minitab, como histogramas, diagramas de caja, diagramas circulares, y gráficos de dispersión.
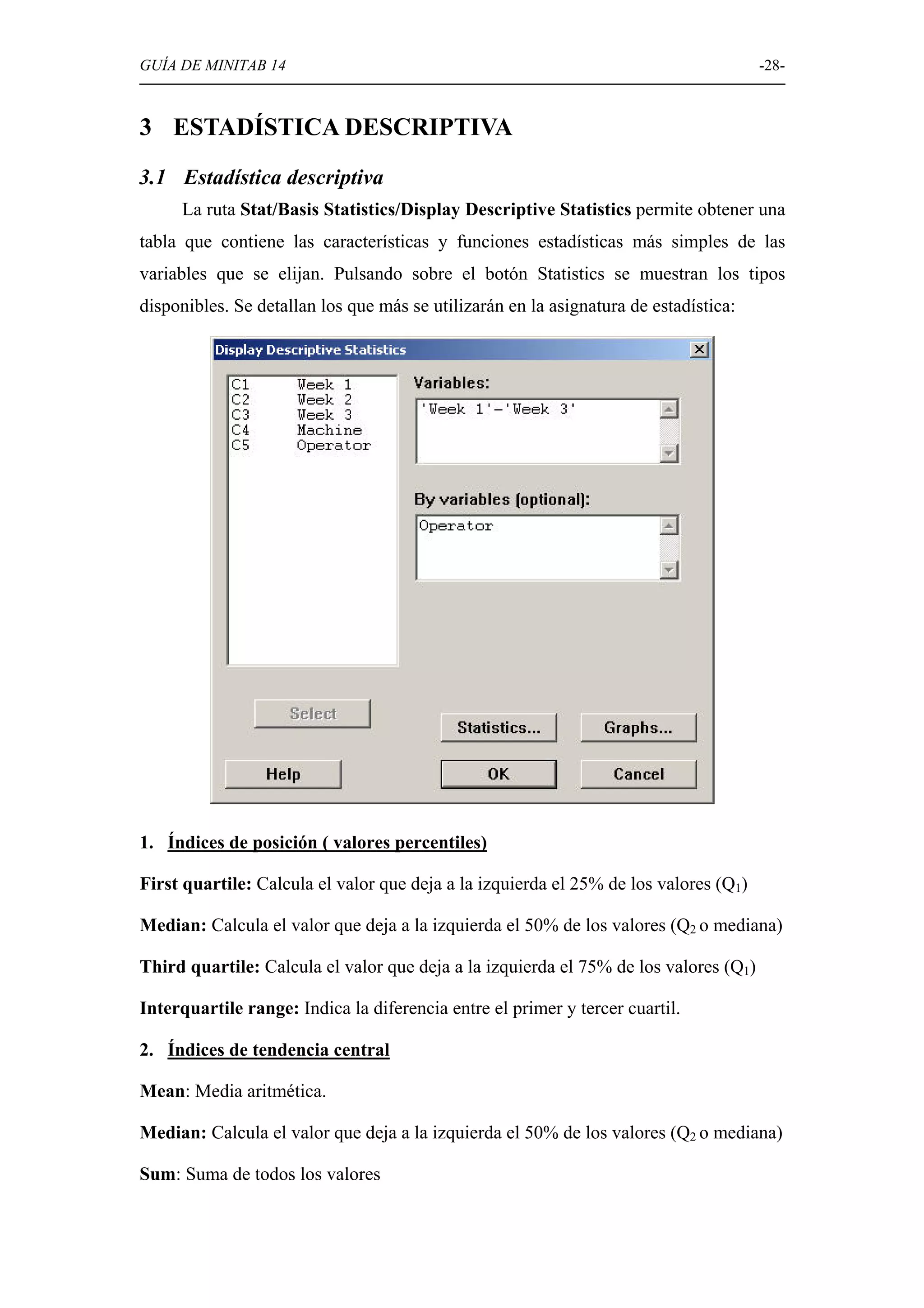
Guía sobre la obtención de estadísticas descriptivas en Minitab, incluyendo índices de posición, tendencia central y dispersión.
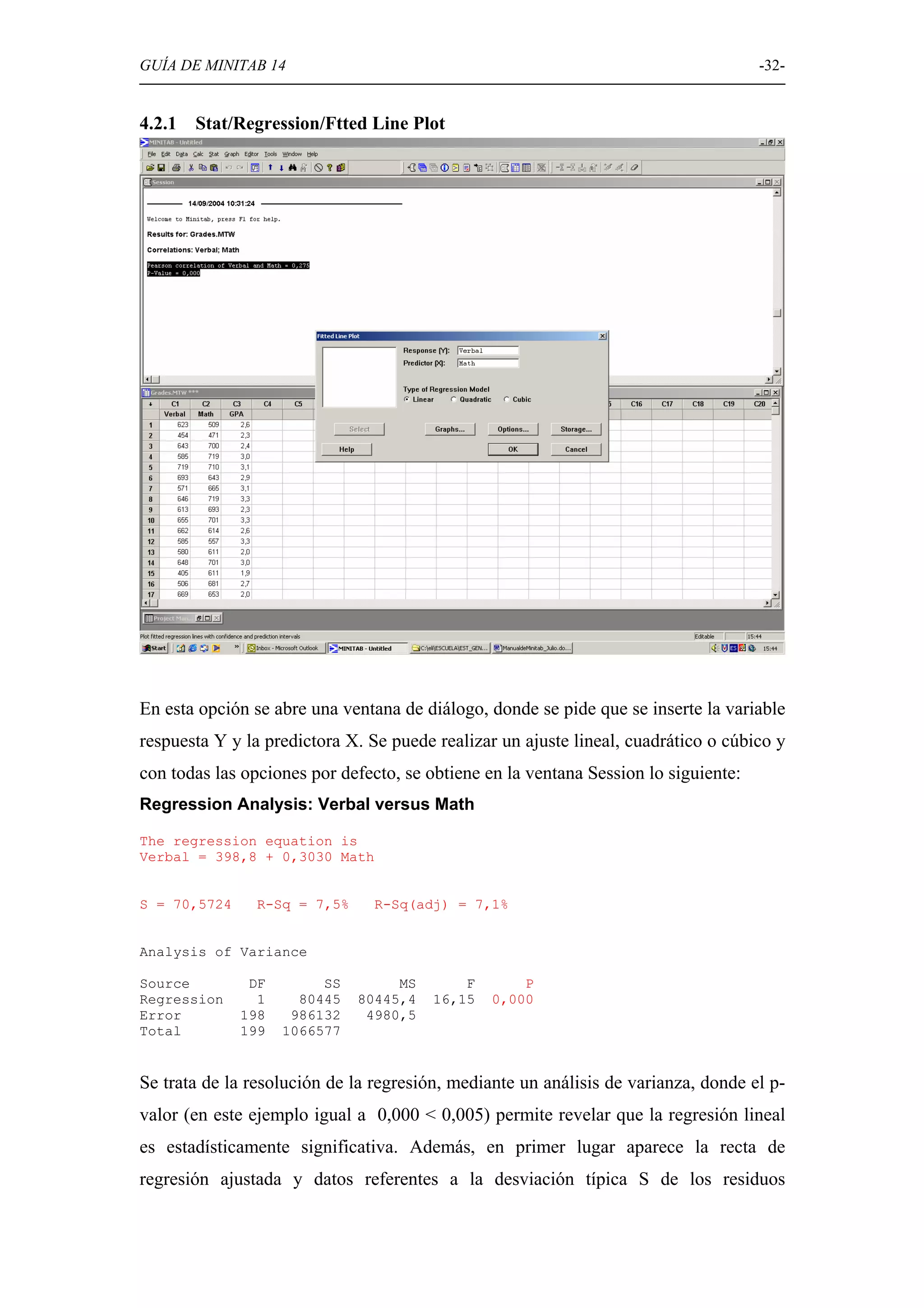
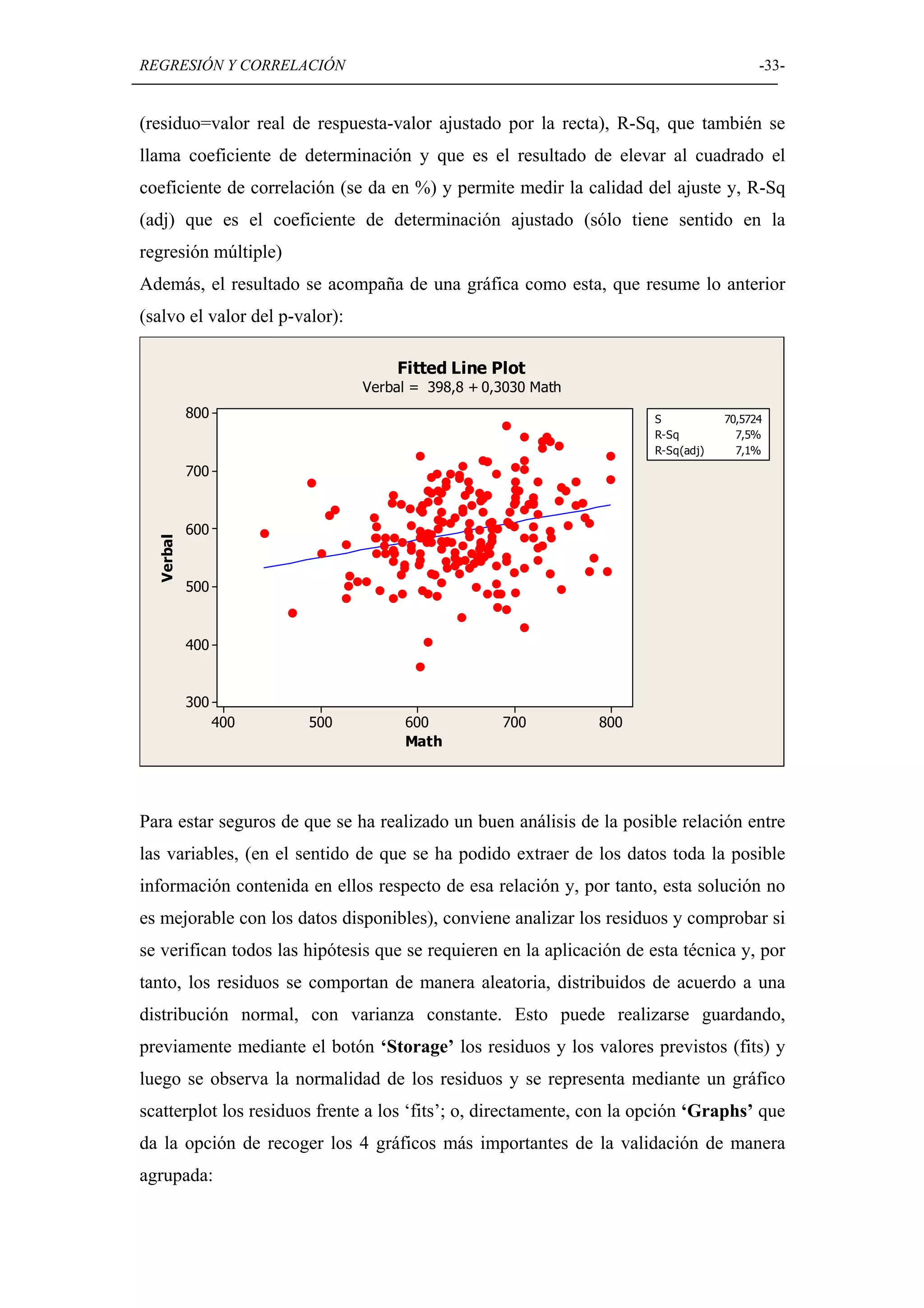
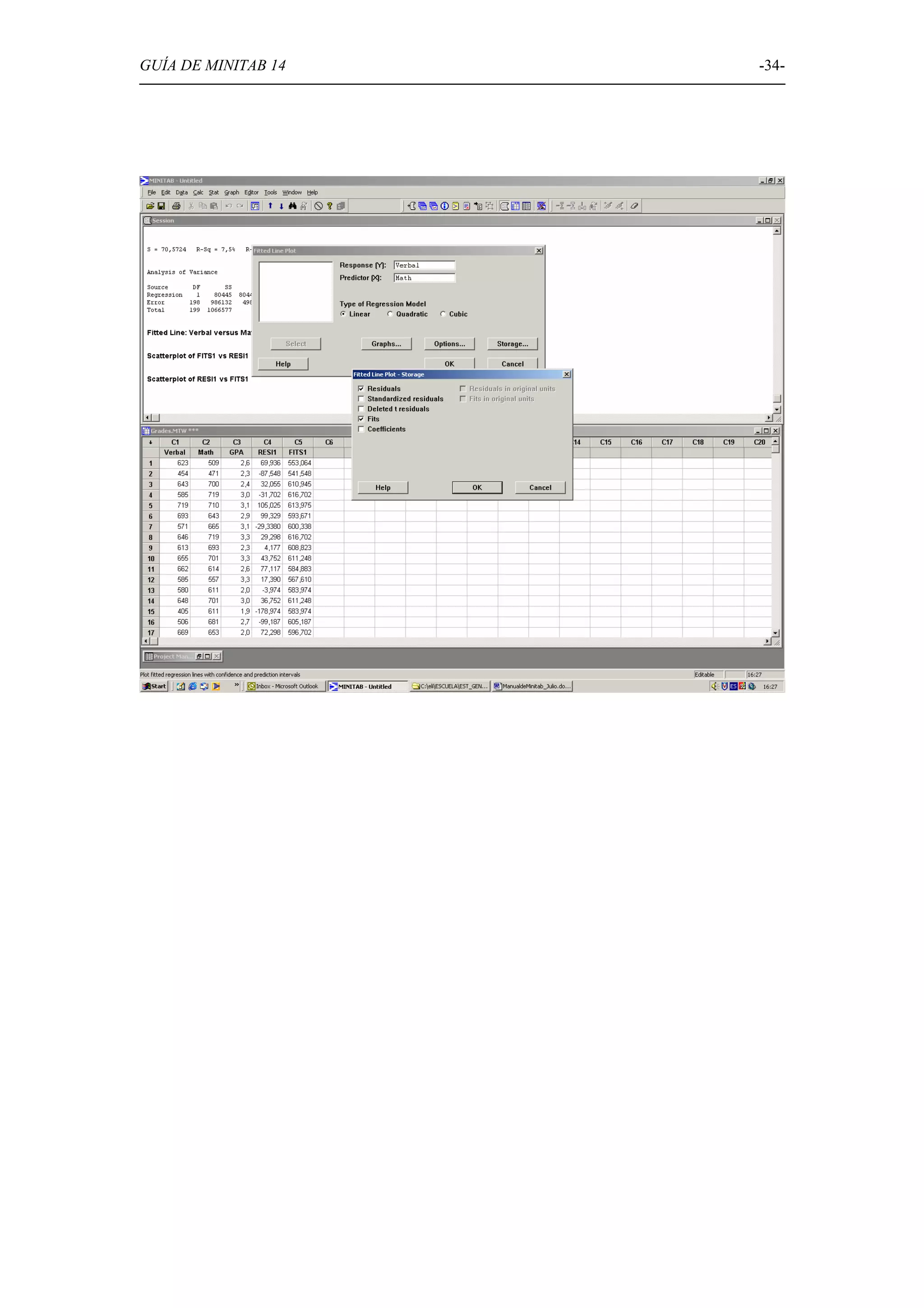
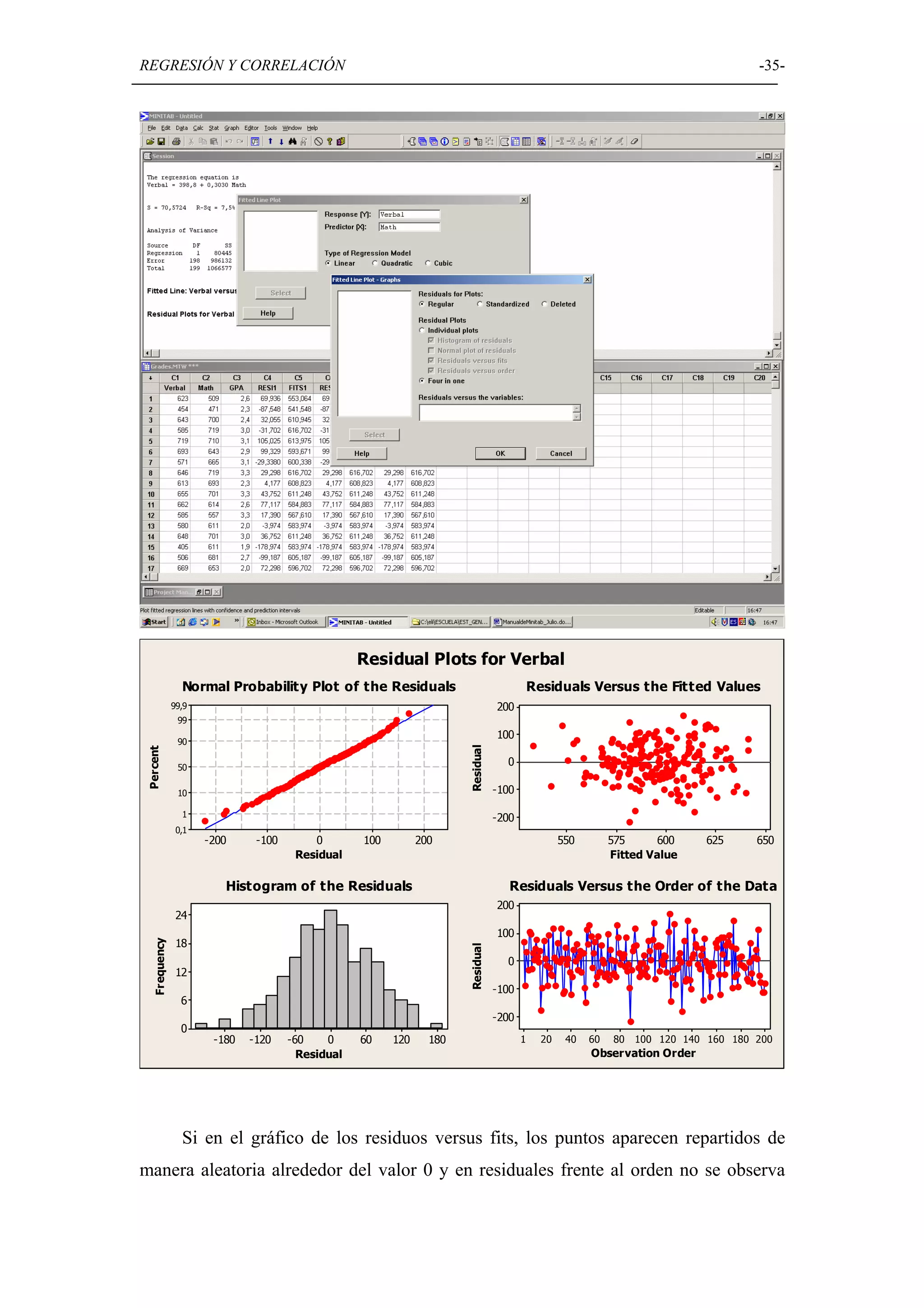
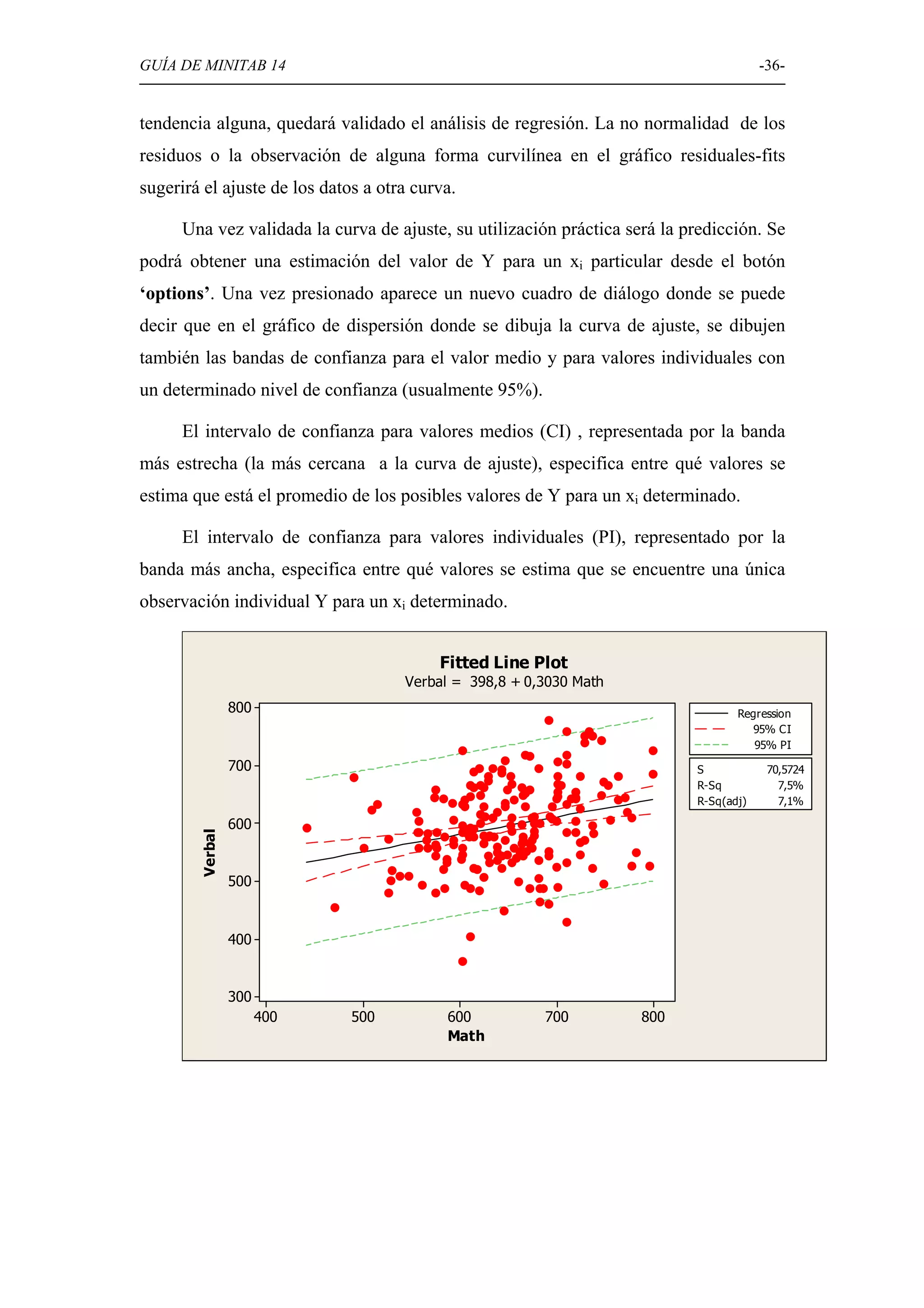
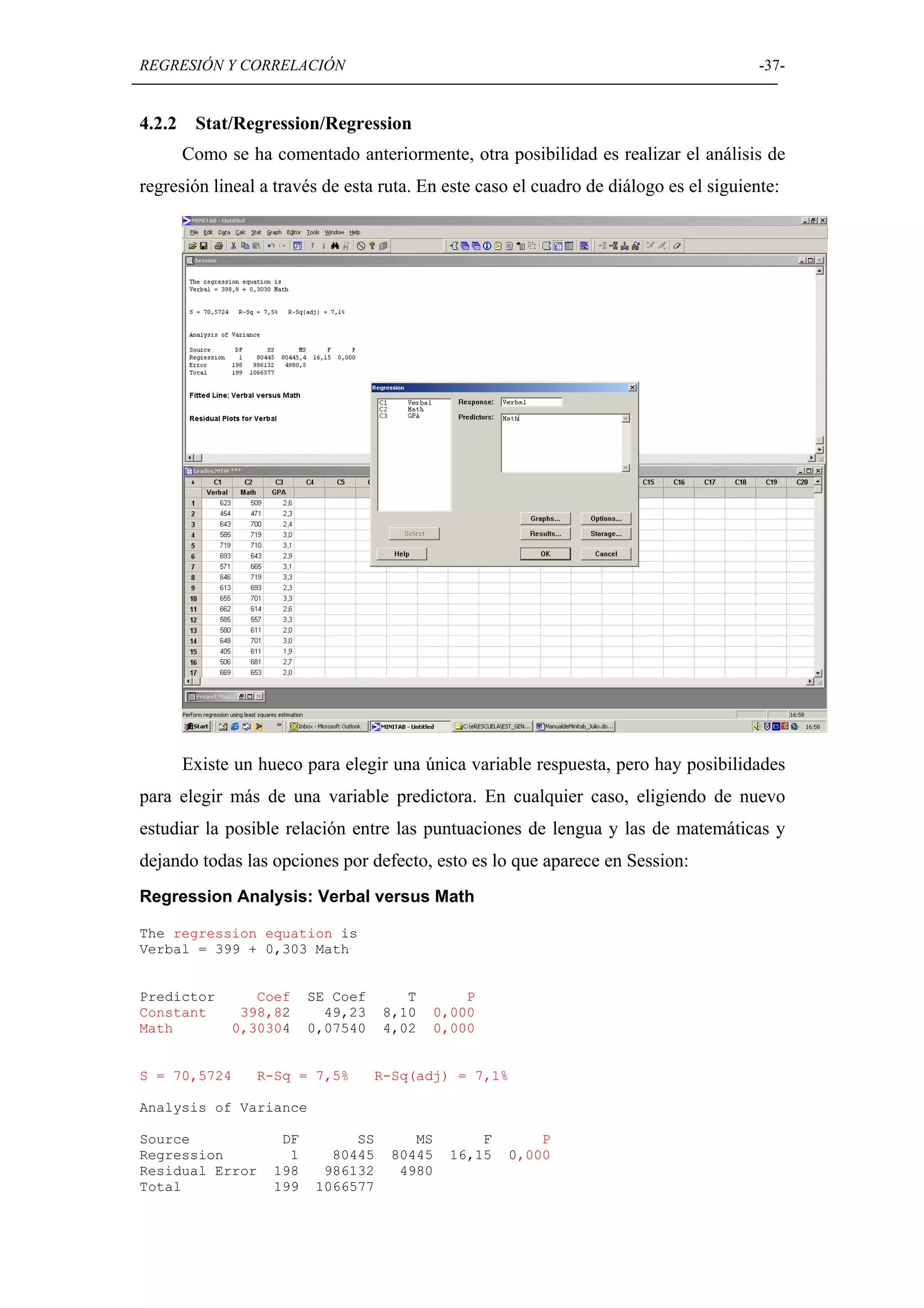
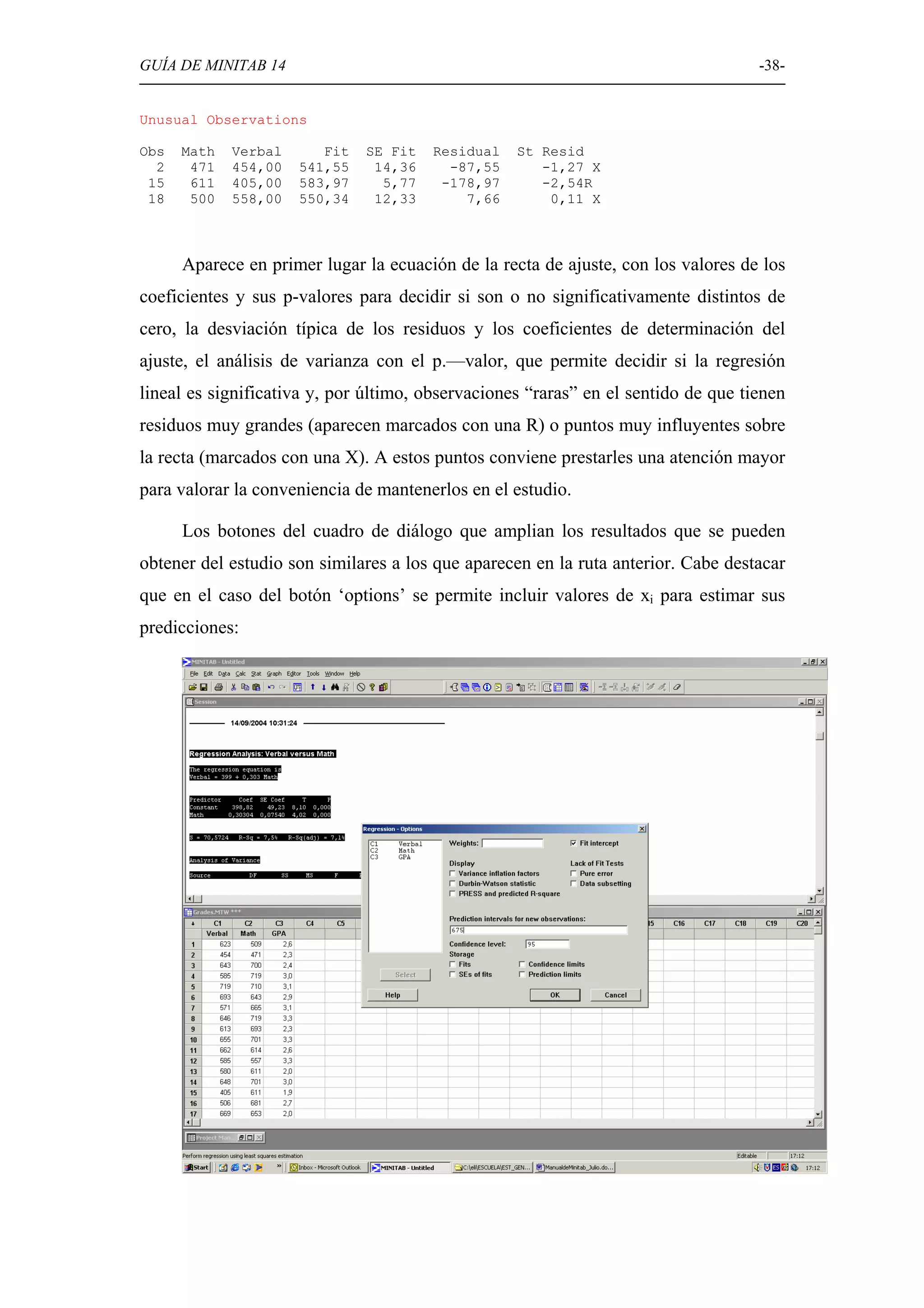
Detallado de técnicas de regresión lineal y correlación, incluyendo ajustes y análisis de varianza.
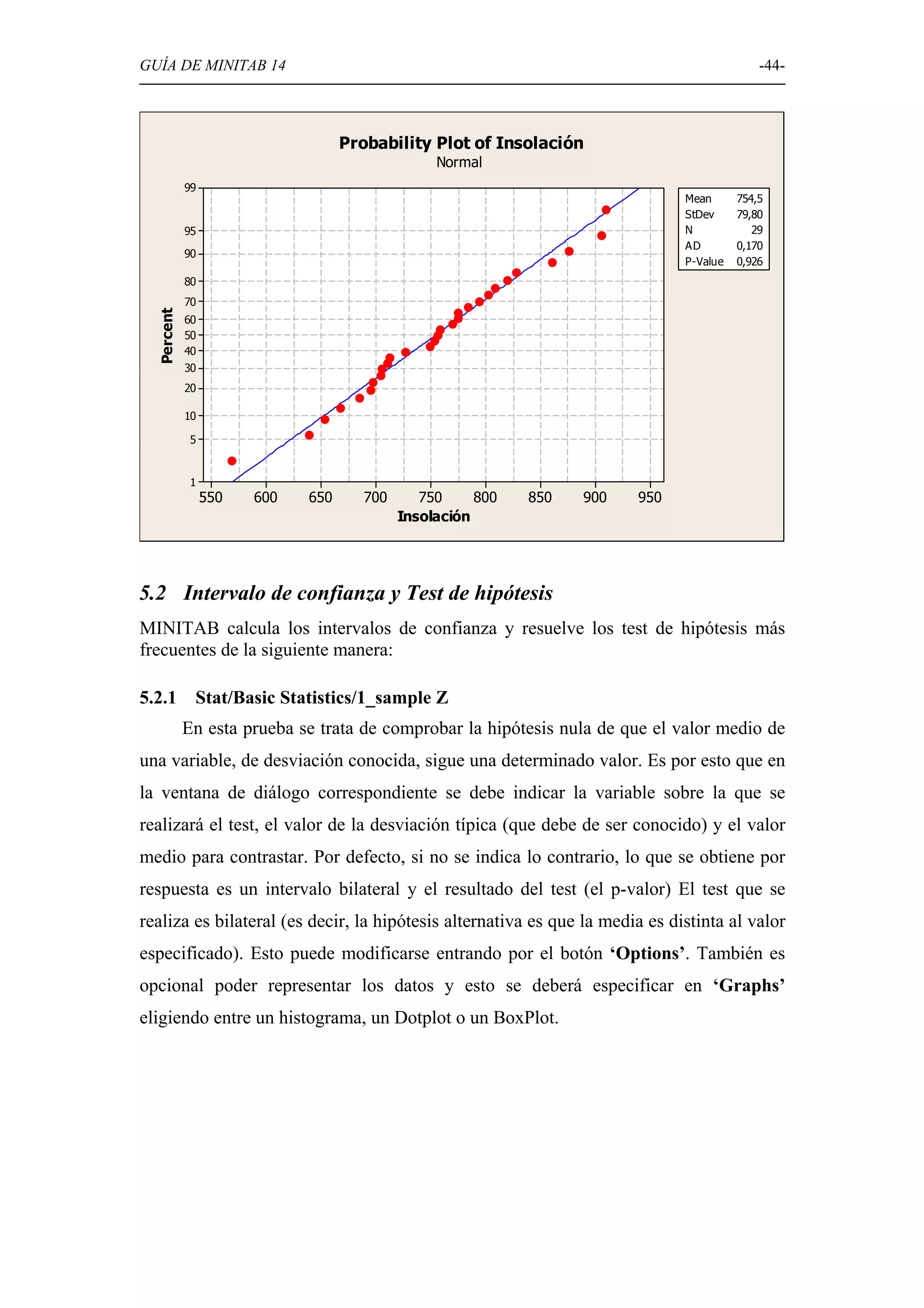
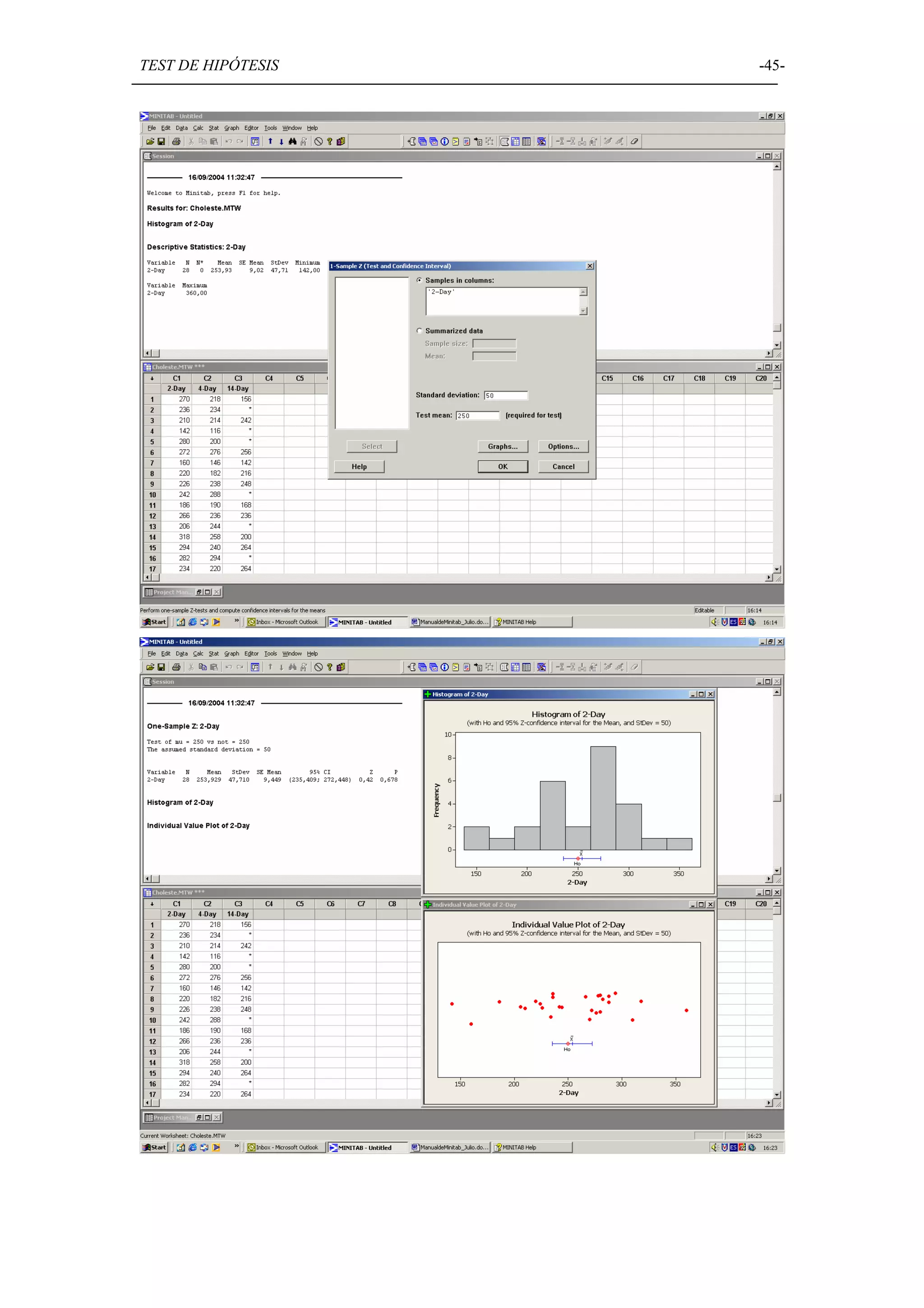
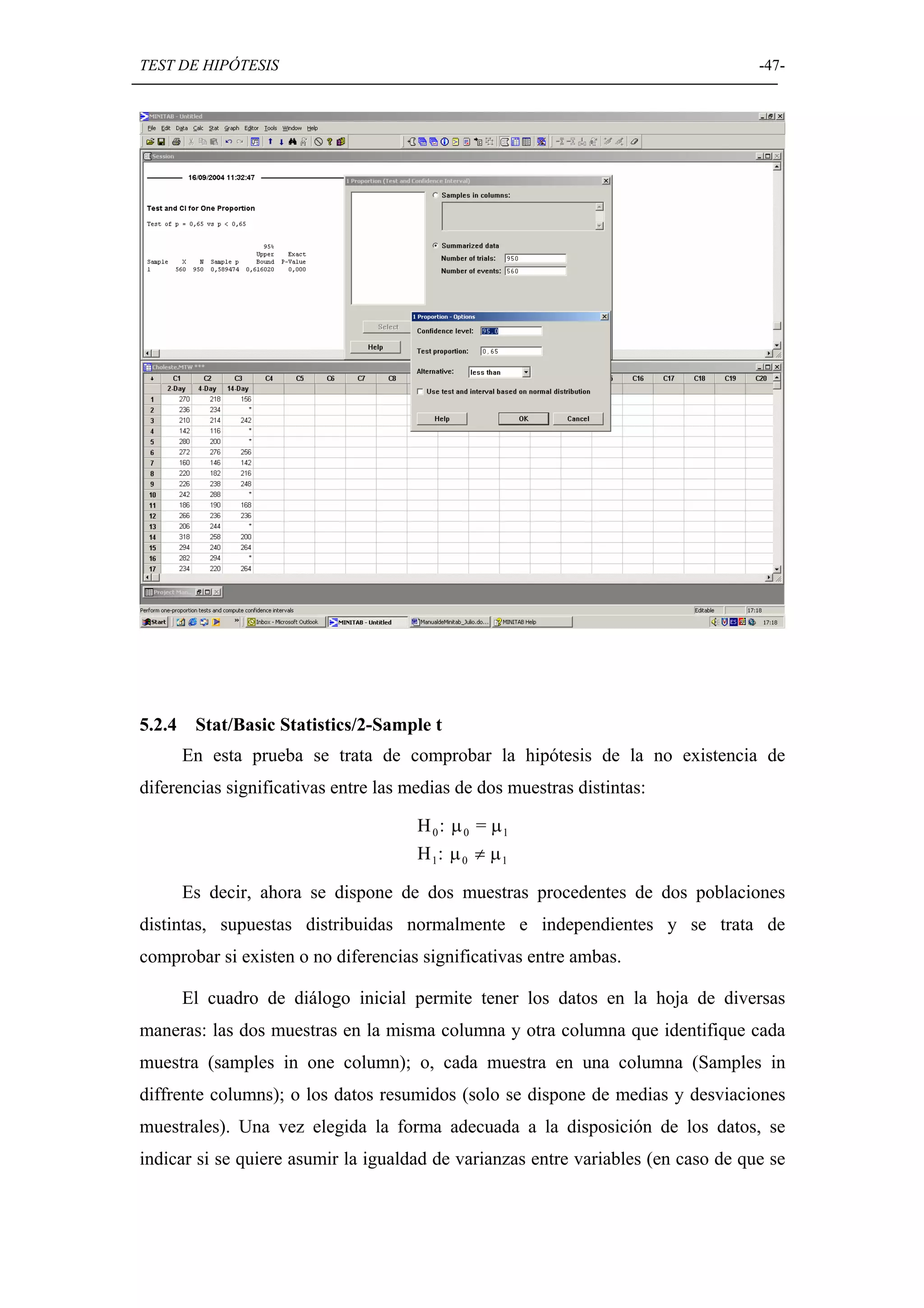
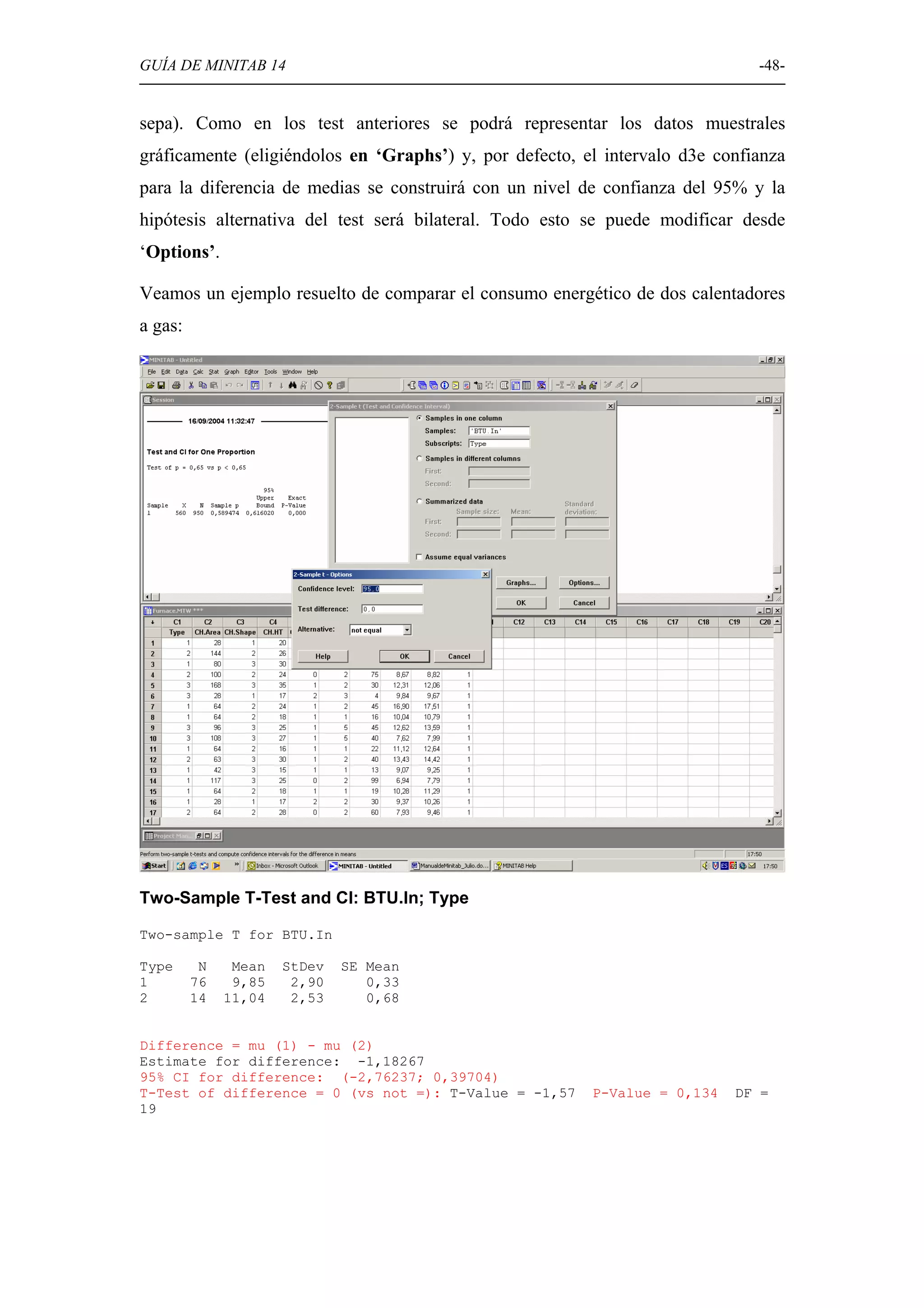
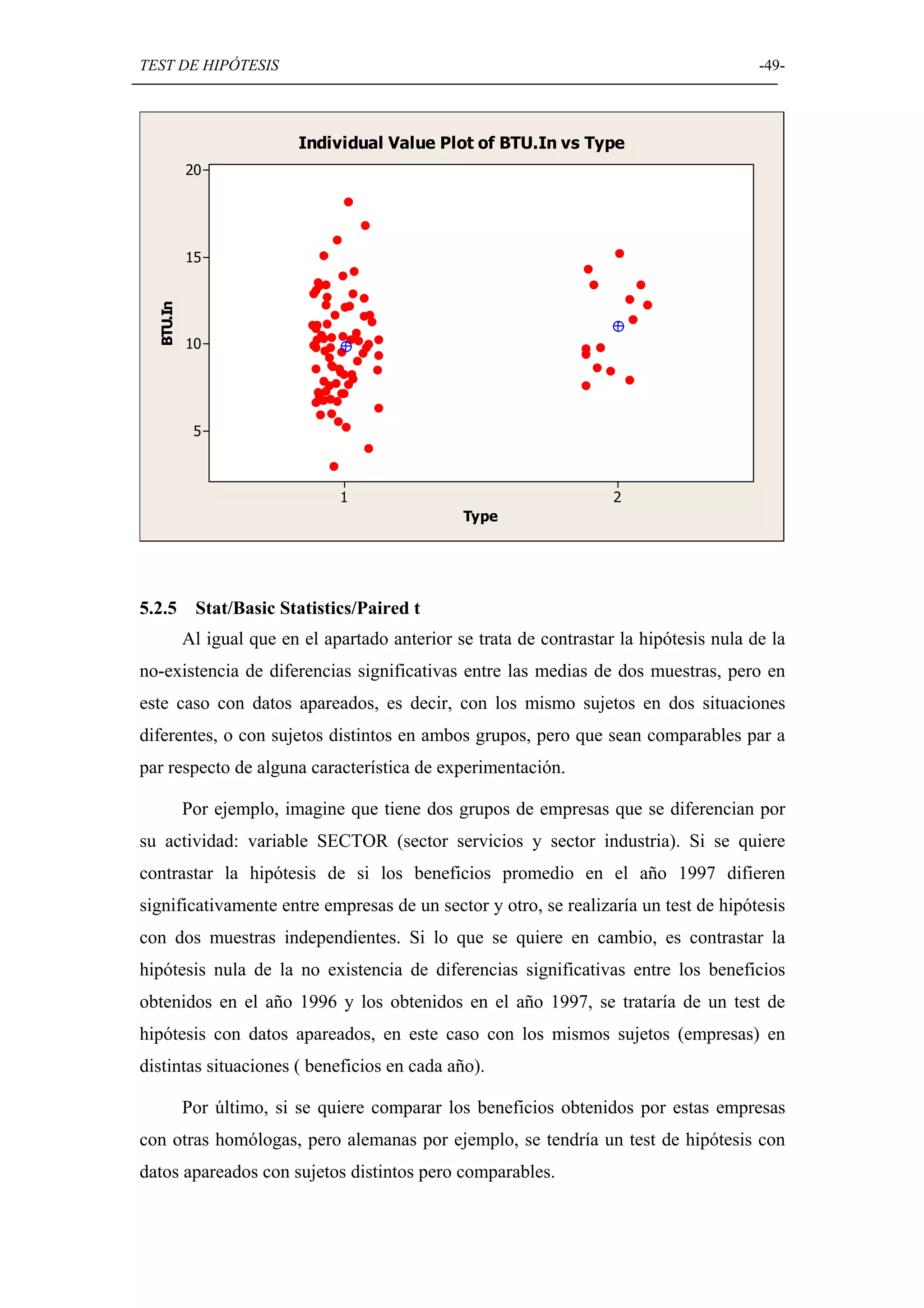
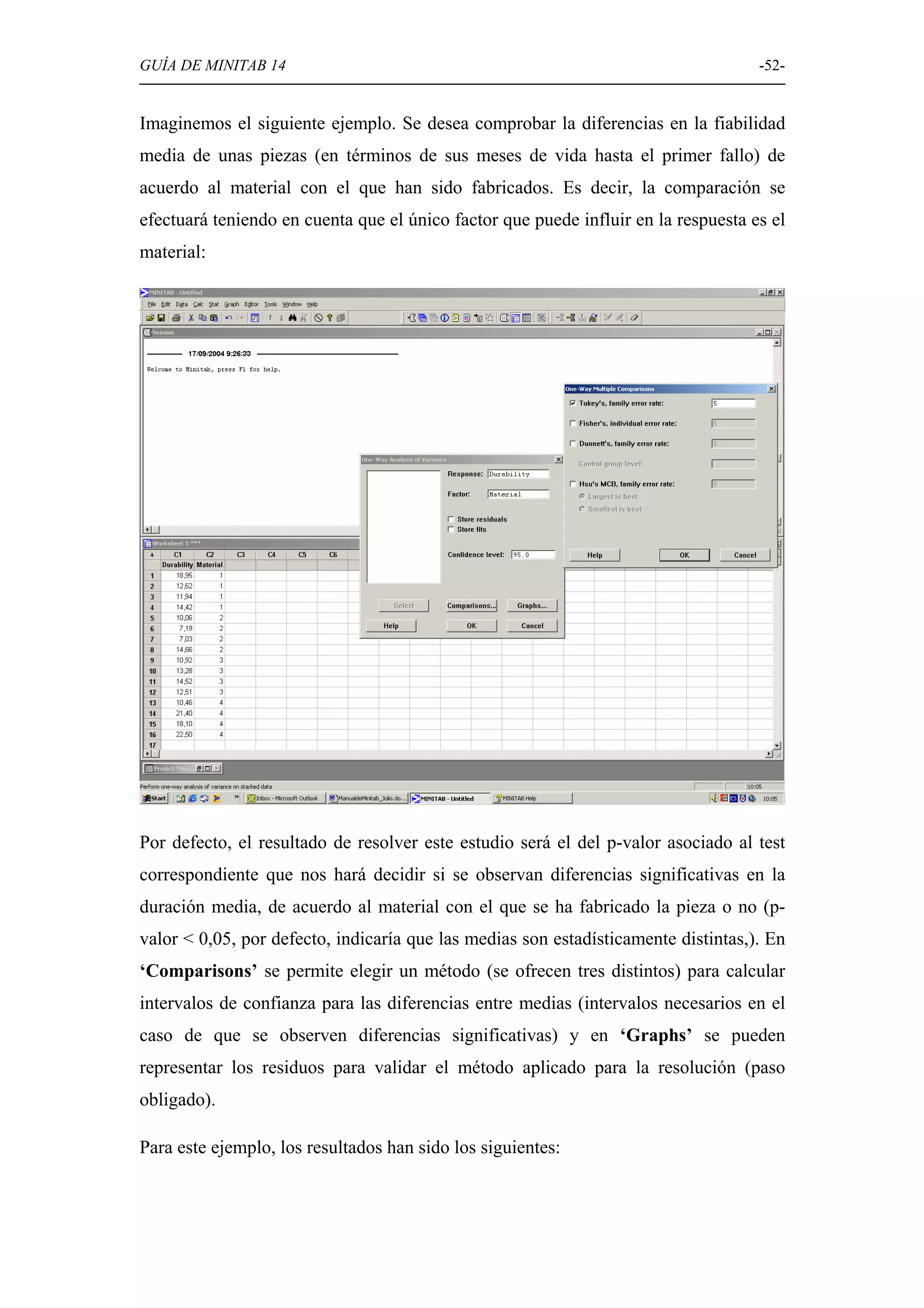
Discusión sobre la prueba de hipótesis en Minitab, incluyendo normalidad, comparación de medias y varianzas.
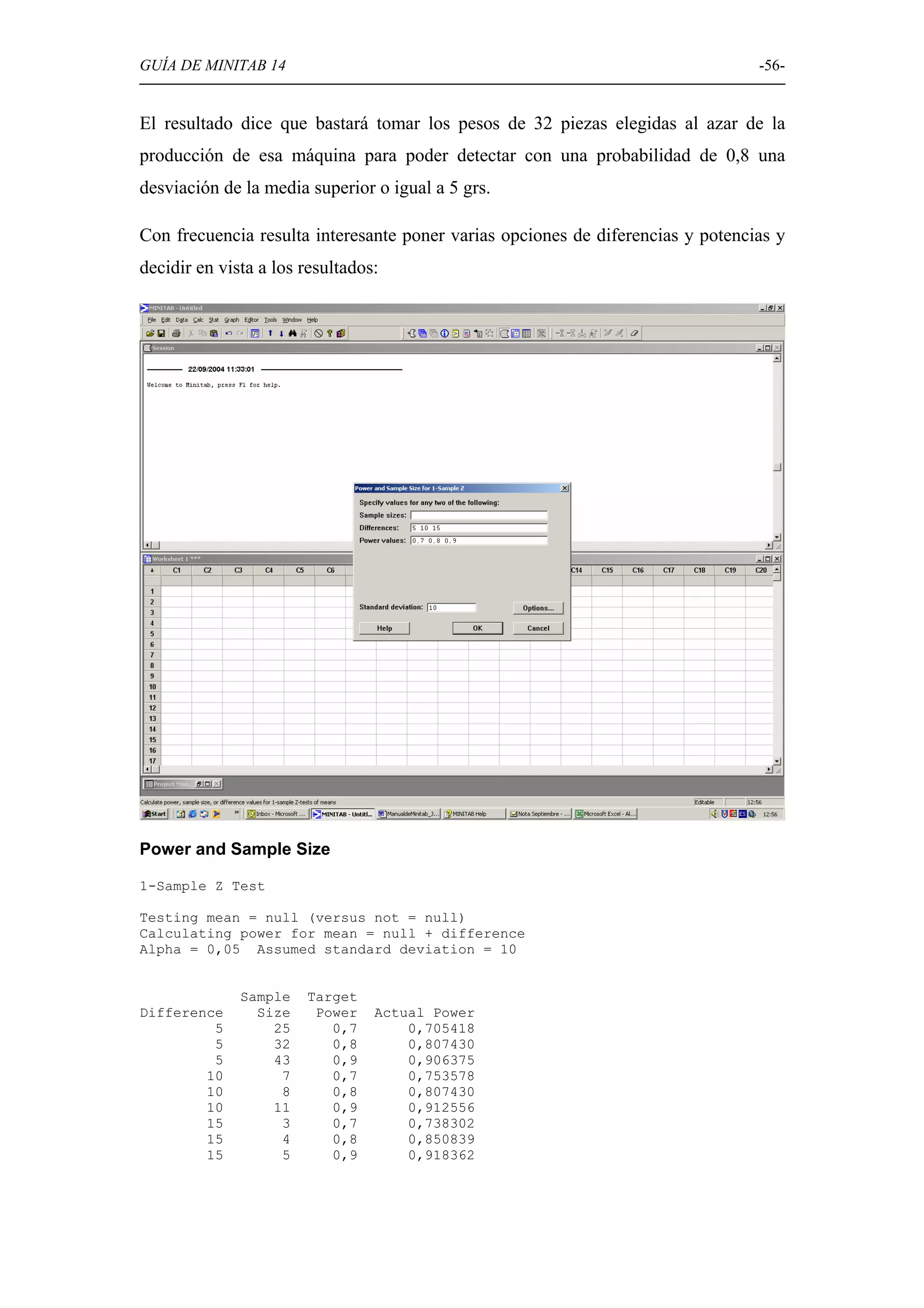
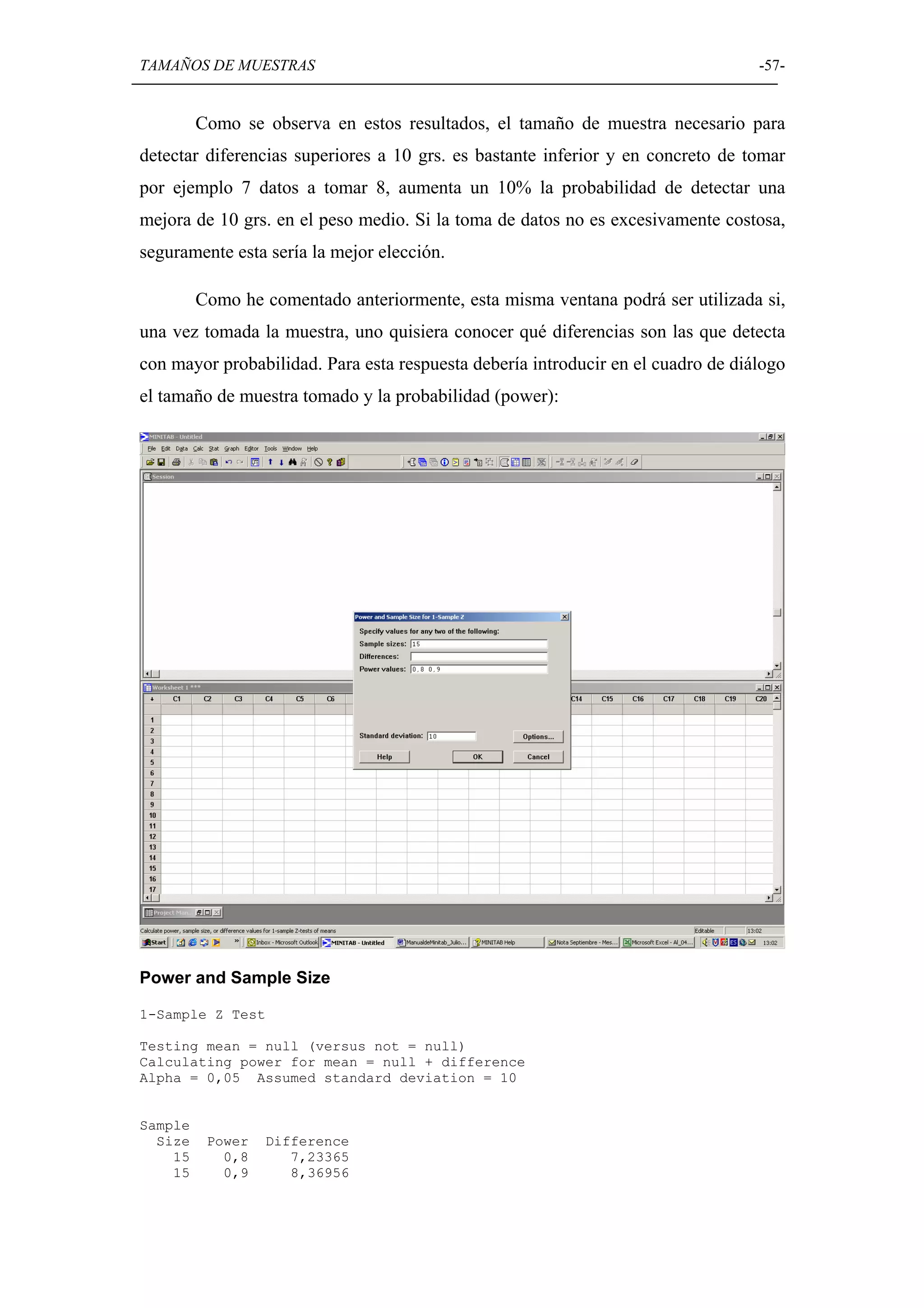
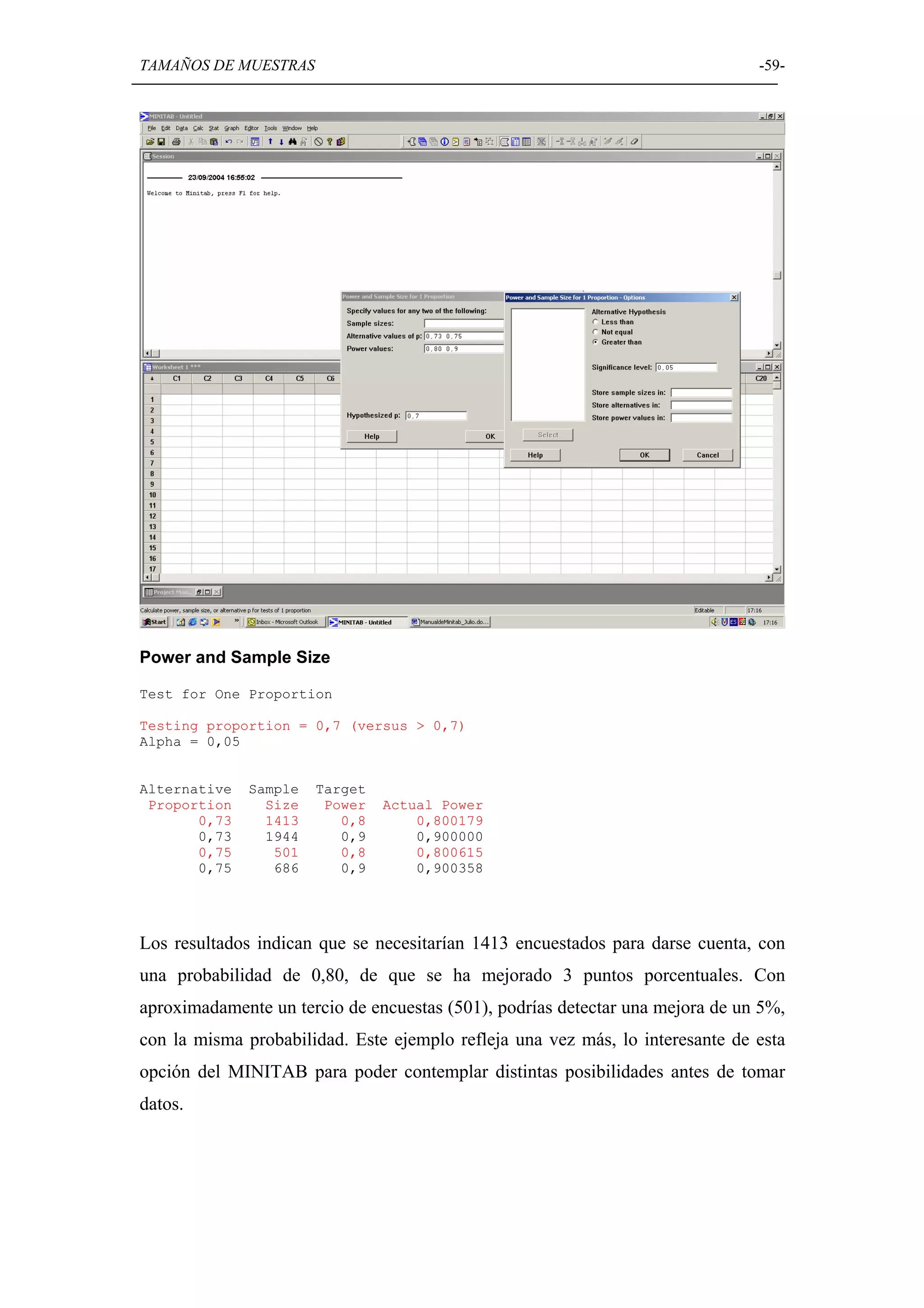
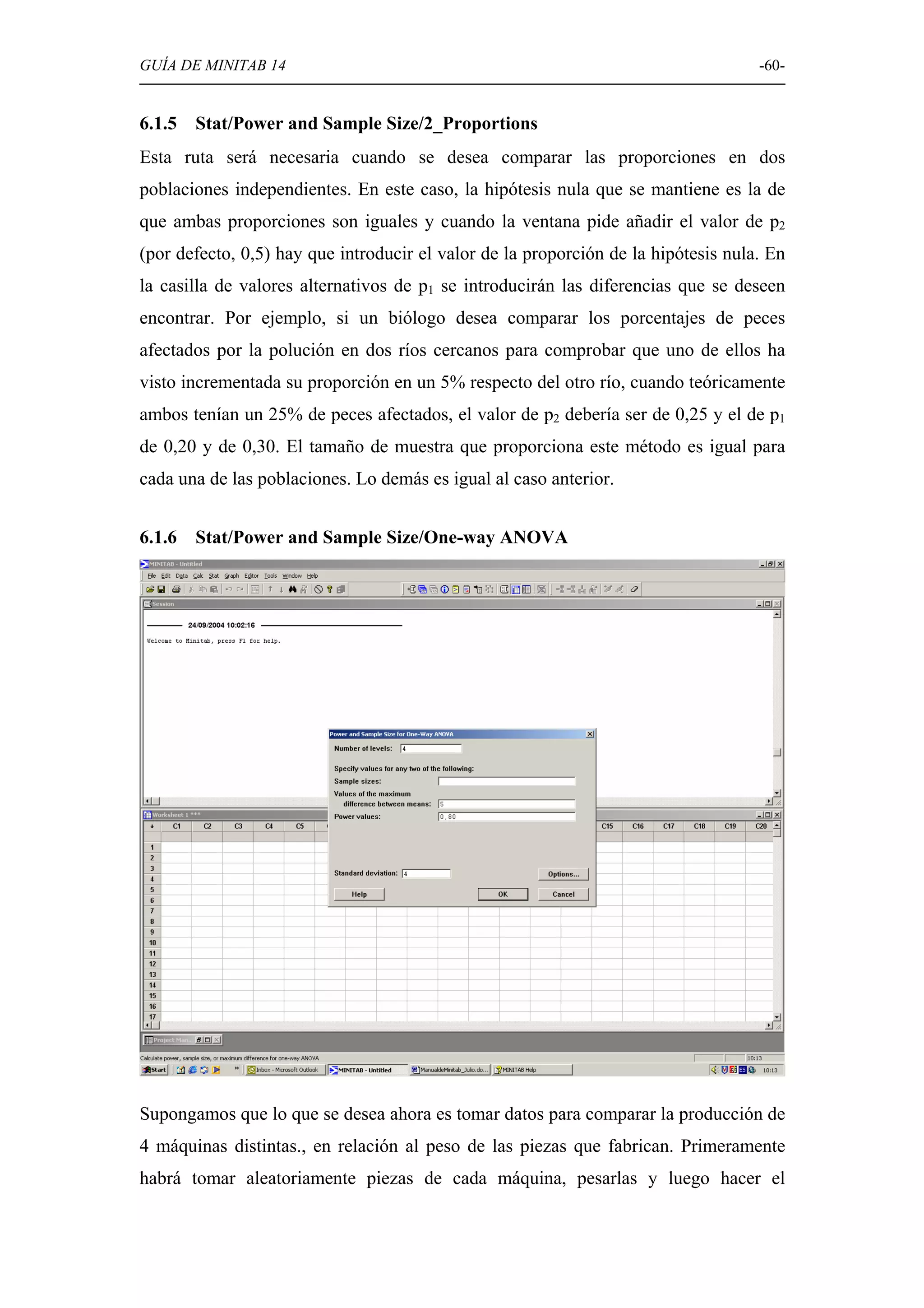
Uso de Minitab para determinar el tamaño de muestra adecuado en diferentes pruebas de hipótesis.



































































