Este documento describe diferentes medidas de tendencia central como la media, mediana y moda. Explica cómo calcular la media aritmética para datos agrupados e no agrupados utilizando tablas de frecuencias. También define la mediana y explica cómo calcularla para conjuntos de datos pares e impares, incluyendo cómo calcularla a partir de una tabla de frecuencias cuando hay muchos valores.













![𝑴𝒆𝒅 = 𝑳𝒊𝒏𝒇 + 𝑨.
𝑵
𝟐
− 𝑭𝒊 − 𝟏
𝒇𝒊
𝐋𝐢𝐧𝐟 Límite inferior de la clase que contiene la mediana
A Ancho de clase
𝐧
𝟐
Intervalo que contiene la mediana
Fi-1
Frecuencia absoluta acumulada anterior al intervalo que tiene la
mediana
fi Frecuencia absoluta del intervalo que contiene la mediana
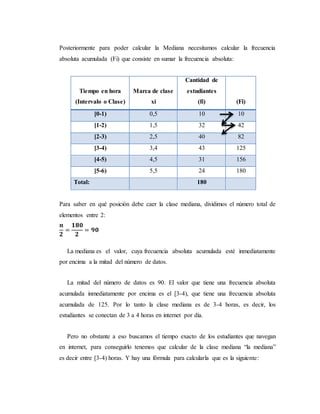
Sustituimos los valores:
1.-
180
2
= 90
2.- 𝑀𝑒𝑑 = 3 + 1. [
90−82
43
]
3.- Med= 3 + 1.
8
43
4.- Med= 3 +
8
43
5.- Med= 3 + 0,186
6.- Med= 3,18 Según el resultado obtenido de la Media, los alumnos se conectan
aproximadamente 3 horas con y 18 minutos por días.
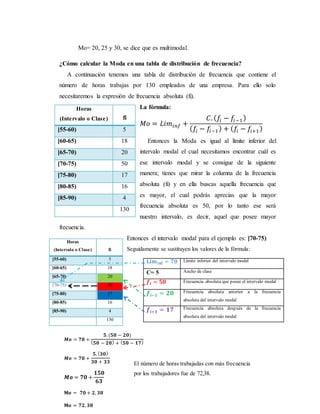
La Moda:
La moda es el dato que más se repite o el dato que ocurre con mayor frecuencia.
Un grupo de datos puede no tener moda, tener una moda (unimodal), dos modas
(bimodal) o más de dos modas (multimodal).
De lo anterior se infiere que en una muestra para que haya moda, tiene que existir
por lo menos un dato que se repita una cantidad de veces mayor que la que aparecen
los demás. Por tanto, en una muestra la moda puede o no existir, y si existe puede ser
única o no. Se puede calcular para cualquier escala de medición de la variable que se
estudia. Para denotar la moda de una variable X, se usará la notación Mo.](https://image.slidesharecdn.com/8zg1hocksuasjawj5qim-signature-4c2a64f8bb1c38a61441bdca958fa7f8a3e067f2229ea110cd7aee051f0d2f36-poli-201209170743/85/Medidas-de-tedencia_central_posicion_y_dispersion-pdf-15-320.jpg)










![Desviación Media:
La desviación Media o Desviación absoluta promedio, es la media aritmética de
las desviaciones absolutas de cada una de las variables con respecto a su valor central,
la media aritmética, o la mediana. Cuanto mayor es su valor, mayor es la dispersión
de los datos. Cuanta más alta sea una medida de dispersión, menos representativa será
la medida de centralización. La desviación media se representa por: 𝐷 𝑋̅ 𝑜 𝐷 𝑚
La desviación respecto a la media es la diferencia entre cada valor de la variable
estadística y la media aritmética. La desviación media es la media aritmética de
los valores absolutos de las desviaciones respecto a la media. Su formulación
matemática es la siguiente:
Sean los datos: 𝑋1, 𝑋2, 𝑋3, 𝑋,4,….., 𝑋 𝑛; relativos a una muestra, entonces, la desviación
media está dado por:
Para datos no agrupados:
𝐷 𝑚 =
∑[ 𝑋𝑖−𝑋̅]
N
Desglosamos la fórmula para entenderla mejor:
Entonces:
𝐷 𝑚 =
[ 𝑋1−𝑋̅]+[ 𝑋2−𝑋̅]+[ 𝑋3−𝑋̅]+⋯..+[ 𝑋 𝑛−𝑋̅]
N
Ejemplo: Halle las Desviación Media de los pesos de 8 niños (en Kg):
15 12 10 18 14 22 17 20
Solución:
Determinamos la media: 𝑿̅ =
𝟏𝟓+𝟏𝟐+𝟏𝟎+𝟏𝟒+𝟐𝟐+𝟏𝟕+𝟐𝟎
𝟖
=
𝟏𝟐𝟖
𝟖
= 𝟏𝟔
𝑫 𝒎 =
[ 𝟏𝟓 − 𝟏𝟔] + [ 𝟏𝟐 − 𝟏𝟔] + [ 𝟏𝟎 + 𝟏𝟔] + [ 𝟏𝟒 − 𝟏𝟔] + [ 𝟐𝟐 − 𝟏𝟔] + [ 𝟏𝟕 − 𝟏𝟔] + [ 𝟐𝟎 − 𝟏𝟔]
𝟖
Total de datos: N= 8
∑ = Sumatoria
𝑿𝒊= Datos
𝑿̅= Media aritmética de los datos
N= Total de los datos.](https://image.slidesharecdn.com/8zg1hocksuasjawj5qim-signature-4c2a64f8bb1c38a61441bdca958fa7f8a3e067f2229ea110cd7aee051f0d2f36-poli-201209170743/85/Medidas-de-tedencia_central_posicion_y_dispersion-pdf-28-320.jpg)
![𝑫 𝒎 =
(−𝟏)+(−𝟒)+(−𝟔)+( 𝟐)+(−𝟐)+( 𝟔)+( 𝟏)+( 𝟒)
𝟖
Los valores negativos cambian a positivo
𝑫 𝒎 =
𝟏+𝟒+𝟔+𝟐+𝟔+𝟏+𝟒
𝟖
=
𝟐𝟔
𝟖
= 𝟑, 𝟐𝟓
Para datos agrupados:
𝐷 𝑚 =
∑[ 𝑋𝑖 − 𝑋̅]. 𝑓𝑖
N
Desglosamos la fórmula para entender la mejor:
Entonces:
𝐷 𝑚 =
[ 𝑋1−𝑋̅].𝑓1+[ 𝑋2−𝑋̅].𝑓2+[ 𝑋3−𝑋̅].𝑓3+⋯..+[ 𝑋 𝑛−𝑋̅].𝑓𝑛
N
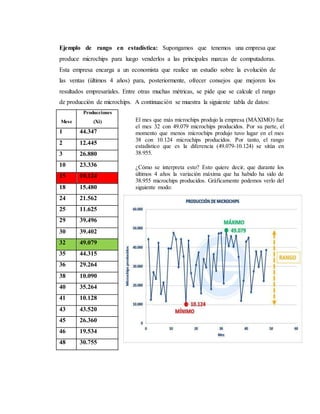
Ejemplo: Calcular la Desviación Media de la distribución
Clase o Intervalos 𝑿𝒊 𝒇𝒊 𝑿𝒊. 𝒇𝒊 𝑿𝒊 − 𝑿̅ [ 𝑿𝒊 − 𝑿̅]. 𝒇𝒊
[10-15) 12.5 3 37.5 12.7 38.1
[15-20) 17.5 5 87.5 7.7 38.5
[20-25) 22.5 7 157.5 2.7 18.9
[25-30) 27.5 4 110 2.3 9.2
[30-35) 32.5 2 65 7.3 14.6
[35-40) 37.5 6 225 12.3 73.8
∑ 𝐓𝐨𝐭𝐚𝐥: 27 682.5 193.1
𝑿̅ =
∑ 𝑿 𝒊.𝒇𝒊
𝑵
𝑿̅ =
𝟔𝟖𝟐.𝟓
𝟐𝟕
= 𝟐𝟓. 𝟐
∑ = Sumatoria
𝑿𝒊= Marca de Clase
𝑿̅= Media aritmética de los datos
𝑓𝑖= Frecuencia absoluta
N= Total de los datos.
𝐷 𝑚 =
∑[ 𝑋𝑖−𝑋̅].𝑓𝑖
N
Entonces el resultado sería:
𝑫 𝒎 =
𝟏𝟗𝟑.𝟏
𝟐𝟕
= 𝟕. 𝟏𝟓](https://image.slidesharecdn.com/8zg1hocksuasjawj5qim-signature-4c2a64f8bb1c38a61441bdca958fa7f8a3e067f2229ea110cd7aee051f0d2f36-poli-201209170743/85/Medidas-de-tedencia_central_posicion_y_dispersion-pdf-29-320.jpg)

![Para datos agrupados
𝑺 𝟐
=
∑( 𝑿𝒊 − 𝑿̅) 𝟐
. 𝒇𝒊
𝑵 − 𝟏
Desglosamos la fórmula para entender la mejor:
Entonces:
𝐒 𝟐 =
∑( 𝐗 𝟏 − 𝐗̅) 𝟐.𝐟𝟏+( 𝐗 𝟐 − 𝐗̅) 𝟐. 𝐟𝟐 + ( 𝐗 𝟑 − 𝐗̅) 𝟐. 𝐟𝟑 + ⋯+ ( 𝐗 𝐧 − 𝐗̅) 𝟐. 𝐟𝐧
𝐍 − 𝟏
Ejemplo: Calcular la varianza de la distribución de la tabla:
𝑿̅ =
∑ 𝑿 𝒊.𝒇𝒊
𝑵
𝑿̅ =
𝟔𝟖𝟐.𝟓
𝟐𝟕
= 𝟐𝟓. 𝟐
Clase o Intervalos 𝑿𝒊 𝒇𝒊 𝑿𝒊. 𝒇𝒊 𝑿𝒊 − 𝑿̅ [ 𝑿𝒊 − 𝑿̅]. 𝒇𝒊 [ 𝑿𝒊 − 𝑿̅] 𝟐 [ 𝑿𝒊 − 𝑿̅] 𝟐
. 𝒇𝒊
[10-15) 12.5 3 37.5 12.7 38.1 161.29 483.87
[15-20) 17.5 5 87.5 7.7 38.5 59.29 296.46
[20-25) 22.5 7 157.5 2.7 18.9 7.29 37.03
[25-30) 27.5 4 110 2.3 9.2 5.29 21.16
[30-35) 32.5 2 65 7.3 14.6 53.29 106.58
[35-40) 37.5 6 225 12.3 73.8 151.29 907.74
∑ 𝐓𝐨𝐭𝐚𝐥: 27 682.5 193.1 1.852.84
∑ = Sumatoria
𝑿𝒊= Marca de Clase
𝑿̅= Media aritmética de los datos
𝑓𝑖= Frecuencia absoluta
N= Total de los datos.
𝑺 𝟐
=
∑( 𝑿 𝒊−𝑿̅) 𝟐.𝒇𝒊
𝑵−𝟏
𝑺 𝟐
=
𝟏.𝟖𝟓𝟐.𝟖𝟒
𝟐𝟕−𝟏
𝑺 𝟐
=
𝟏.𝟖𝟓𝟐.𝟖𝟒
𝟐𝟔
𝑺 𝟐
= 𝟕. 𝟏𝟐𝟔. 𝟑𝟎𝟕𝟔𝟗𝟐](https://image.slidesharecdn.com/8zg1hocksuasjawj5qim-signature-4c2a64f8bb1c38a61441bdca958fa7f8a3e067f2229ea110cd7aee051f0d2f36-poli-201209170743/85/Medidas-de-tedencia_central_posicion_y_dispersion-pdf-31-320.jpg)




























































