Descargar como PDF, PPTX









![▪ startswith/endswith
▪ strip
▪ split
▪ upper, lower
▪ find, replace, count
▪ join
▪ Slicing
s[0] s[2:7] s[6:] s[:5] s[-1]
▪ String = list, set
contar vocabulario:
len(set(text))
ordenarvocabulario:
sorted(set(text))
▪ módulo re para
expresiones regulares
▪ parsersde fechas
(dateutil)
▪ y mucho mas…](https://image.slidesharecdn.com/pln-python-nltk-130826105449-phpapp01/85/Procesamiento-de-Lenguaje-Natural-Python-y-NLTK-9-320.jpg)


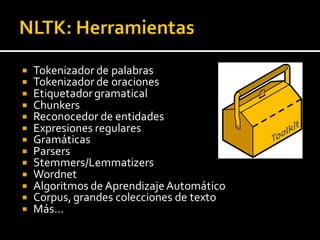
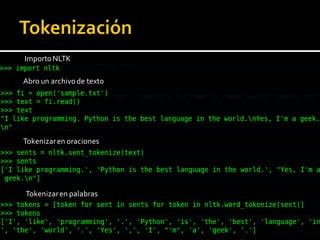
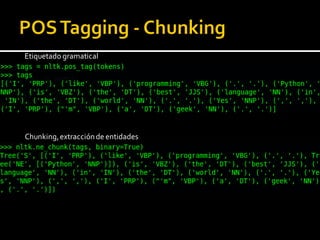
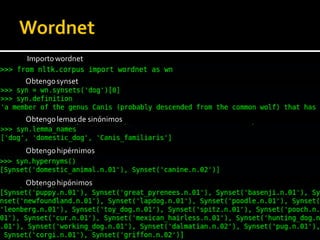
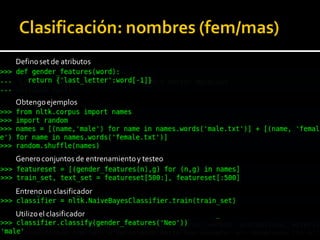



Este documento presenta una introducción a procesamiento de lenguaje natural. Explica algunas aplicaciones clave como traducción automática, clasificación de texto y recuperación de información. También describe áreas como extracción de información, entendimiento de lenguaje natural y corrección automática. Finalmente, resume los principales retos y ventajas del uso de Python para procesamiento de lenguaje natural.



































































