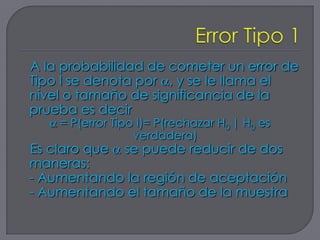
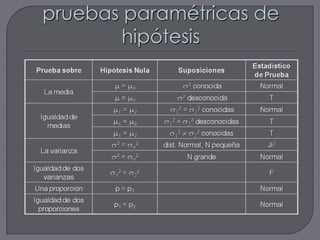
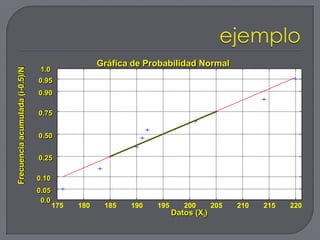
Este documento describe los conceptos básicos de las pruebas de hipótesis. Explica que una prueba de hipótesis involucra proponer una hipótesis nula y alternativa, seleccionar un nivel de significancia, calcular un estadístico de prueba y decidir si se rechaza o no la hipótesis nula. También cubre los diferentes tipos de pruebas de hipótesis paramétricas y no paramétricas, y cómo reportar los resultados usando valores p.