Descargado 110 veces









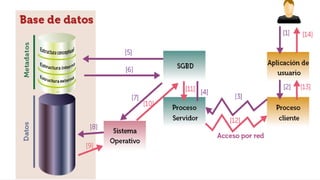


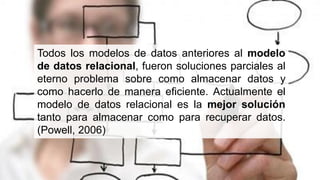
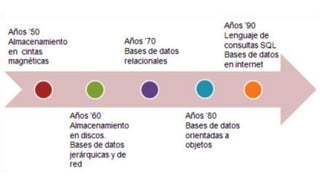


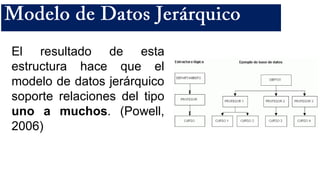

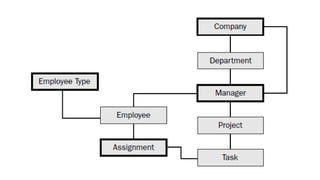

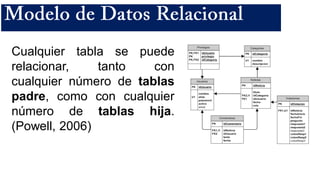



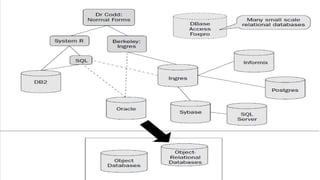

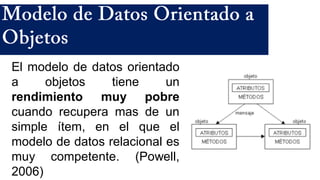








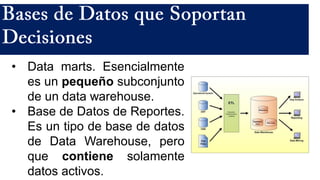


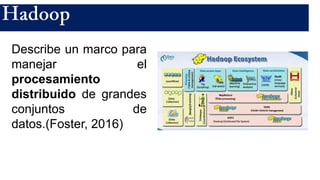











El documento presenta un estudio sobre conceptos fundamentales, evolución, tipos, métodos de diseño y ventajas de los sistemas de bases de datos, centrándose en la importancia del modelo de datos relacional. Se discuten las características de las bases de datos transaccionales y de soporte a la toma de decisiones, así como enfoques emergentes como NoSQL. Finalmente, se delinean los pasos necesarios para el diseño de bases de datos y las ventajas que ofrecen frente a otros métodos de almacenamiento de datos.