Descargado 165 veces

































































![trainbpx Entrena redes multicapa con retropropagación rápida. Se puede usar para redes de una,dos o tres capas. Ejemplo use la funcion trainbpx para una red de dos capas. [W1,b1,W2,b2,epochs,tr] = trainbpx (W1,b1,’tansig’, W2,b2,’purelin’,p,t,tp) Método del Momento y Aprendizaje Variable](https://image.slidesharecdn.com/1mejorasbpn1-090922013141-phpapp02/85/Variantes-de-BACKPROPAGATION-71-320.jpg)
![Valores por omisión para tp tp= [disp-freq = 25 max-epoch= 100 err-goal= 0.02 lr= 0.01 momentum= 0.9 lr-inc= 1.05 lr-dec= 0.7 err-ratio= 1.04 ]](https://image.slidesharecdn.com/1mejorasbpn1-090922013141-phpapp02/85/Variantes-de-BACKPROPAGATION-72-320.jpg)
![%EJEMPLO: OR EXCLUSIVA clear;echo on;clc;NNTWARN OFF; P = [0 0 1 1 ;0 1 0 1]; T = [0 1 1 0 ]; [w1,b1,w2,b2]=initff(P,2, 'tansig' ,1, 'purelin' ) [w1, b1,w2,b2,epochs]= trainbpx(w1,b1, 'tansig' ,w2,b2, 'purelin' ,P,T)](https://image.slidesharecdn.com/1mejorasbpn1-090922013141-phpapp02/85/Variantes-de-BACKPROPAGATION-73-320.jpg)
![[a1,a2]=simuff(P,w1,b1, 'tansig' ,w2,b2, 'purelin' ) pause %Pulse una tecla para graficar la solución plotpv(P,T); plotpc(w1,b1); plotpc(w2,b2); echo off](https://image.slidesharecdn.com/1mejorasbpn1-090922013141-phpapp02/85/Variantes-de-BACKPROPAGATION-74-320.jpg)

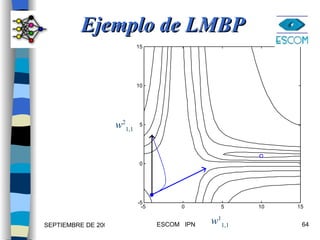
![Ejemplo use la funcion trainlm para una red de dos capas. [W1,b1,W2,b2,epochs,tr] = trainlm (W1,b1,’tansig’, W2,b2,’purelin’,P,T,tp) Parámetros opcionales para tp= Frecuencia de muestreo = 25; # Máximo de épocas= 1000; Sumatoria del error cuadrático=0.02;](https://image.slidesharecdn.com/1mejorasbpn1-090922013141-phpapp02/85/Variantes-de-BACKPROPAGATION-76-320.jpg)

![%EJEMPLO: OR EXCLUSIVA clear;echo on;clc;NNTWARN OFF; P = [0 0 1 1 ;0 1 0 1]; T = [0 1 1 0 ]; [w1,b1,w2,b2]=initff(P,2, 'tansig' ,1, 'purelin' ) [w1, b1,w2,b2,epochs]= trainlm(w1,b1, 'tansig' ,w2,b2, 'purelin' ,P,T)](https://image.slidesharecdn.com/1mejorasbpn1-090922013141-phpapp02/85/Variantes-de-BACKPROPAGATION-78-320.jpg)
![[a1,a2]=simuff(P,w1,b1, 'tansig' ,w2,b2, 'purelin' ) pause %Pulse una tecla para graficar la solución plotpv(P,T); plotpc(w1,b1); plotpc(w2,b2); echo off](https://image.slidesharecdn.com/1mejorasbpn1-090922013141-phpapp02/85/Variantes-de-BACKPROPAGATION-79-320.jpg)



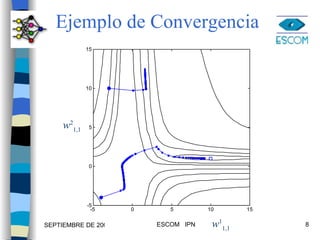
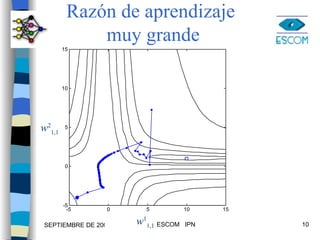
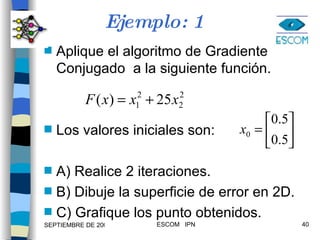
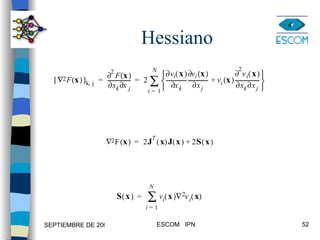
1) El documento describe varias técnicas para mejorar el algoritmo de retropropagación como métodos heurísticos y de optimización numérica. 2) Los métodos heurísticos incluyen momento y razón de aprendizaje variable, mientras que los métodos de optimización son el gradiente conjugado y Levenberg-Marquardt. 3) Se proveen ejemplos para ilustrar la aplicación de estas técnicas.























































































