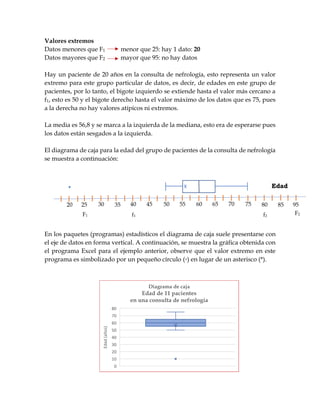
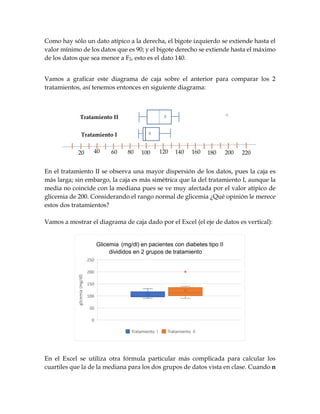
Este documento explica cómo construir y analizar diagramas de cajas para representar y comparar conjuntos de datos. Un diagrama de caja muestra la mediana, los cuartiles y valores atípicos o extremos para proporcionar información sobre la localización, dispersión y forma de una distribución de datos. El documento describe los pasos para construir un diagrama de caja e identificar valores atípicos y extremos, y proporciona ejemplos para ilustrar cómo se pueden usar los diagramas de cajas para comparar grupos de datos.


![7. Determinar los límites F1 y F2 a partir de los cuales se considera que un dato
es un valor extremo:
F1 = Q1 – 2*(1,5*RI)
F2 = Q3 + 2*(1,5*RI)
8. Ubicar estos límites en el eje
9. Los datos que se encuentren entre los límites entre [F1 - f1] y/o entre [f2 - F2]
se consideran valores atípicos.
10. Los datos mayores que F2 y/o menores que F1 se consideran valores
extremos.
11. Si no hay valores atípicos ni extremos, se extiende una línea desde los
extremos de la caja hasta los valores máximo y mínimo de los datos, esta línea
se llama bigote.
f2f1 F2F1 Q1 Q3Q2
Valores
extremos
Valores
atípicos
Valores
atípicos
f2f1 F2F1 Q1 Q3Q2
Valores
extremos
f2f1 F2F1 Q1 Q3Q2mín máx](https://image.slidesharecdn.com/diagramadecajasydatosatpicos-170515174150/85/Diagrama-de-cajas-y-datos-atipicos-2-320.jpg)