Descargado 22 veces









![Modelos Logit y Probit
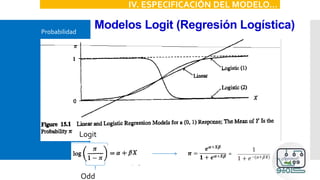
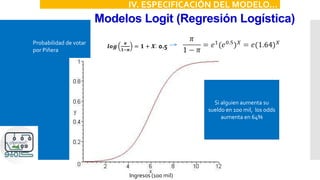
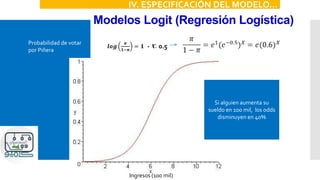
IV. ESPECIFICACIÓN DEL MODELO
P[Y=1|X]=F(X)
•Logit: F es una función de probabilidad logística
•Probit: F es una función de probabilidad normal
acumulada](https://image.slidesharecdn.com/modeloprobit-200221014238/85/Modelos-Logit-y-Probit-con-Stata-14-320.jpg)




![1. Función de Probabilidad logística
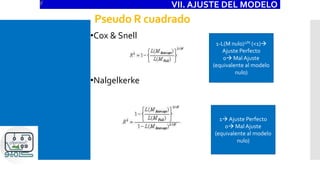
VI. SUPUESTOS
Función de Probabilidad Logística:
P[Y=1]=F(X) con F logística
Consecuencia del no cumplimiento del supuesto: Disminución del ajuste
del modelo.](https://image.slidesharecdn.com/modeloprobit-200221014238/85/Modelos-Logit-y-Probit-con-Stata-20-320.jpg)

















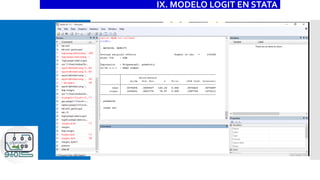
![Ejemplo
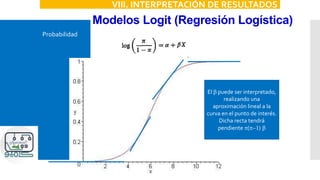
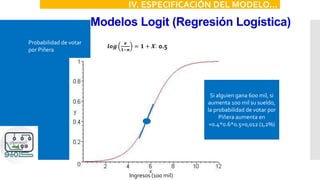
VIII. INTERPRETACIÓN DE RESULTADOS
_cons -1.807127 .0150622 -119.98 0.000 -1.836649 -1.777606
ocupa1 .7317526 .0103442 70.74 0.000 .7114784 .7520269
edad .0338646 .000284 119.24 0.000 .033308 .0344212
pareja2 Coef. Std. Err. z P>|z| [95% Conf. Interval]
_cons .1641249 .0024721 -119.98 0.000 .1593506 .1690423
ocupa1 2.078721 .0215027 70.74 0.000 2.037001 2.121295
edad 1.034445 .0002938 119.24 0.000 1.033869 1.03502
pareja2 Odds Ratio Std. Err. z P>|z| [95% Conf. Interval]
ocupa1 .1630431 .0021776 74.87 0.000 .1587752 .1673111
edad .0075454 .0000527 143.24 0.000 .0074422 .0076487
dy/dx Std. Err. z P>|z| [95% Conf. Interval]
Delta-method
dy/dx w.r.t. : edad ocupa1](https://image.slidesharecdn.com/modeloprobit-200221014238/85/Modelos-Logit-y-Probit-con-Stata-43-320.jpg)

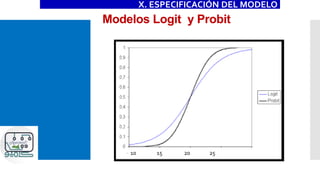
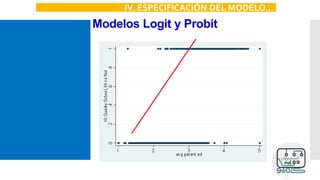
![Modelos Logit y Probit
P[Y=1|X]=F(X)
•Logit: F es una función de probabilidad logística
•Probit: F es una función de probabilidad normal
acumulada
X. ESPECIFICACIÓN DEL MODELO](https://image.slidesharecdn.com/modeloprobit-200221014238/85/Modelos-Logit-y-Probit-con-Stata-48-320.jpg)
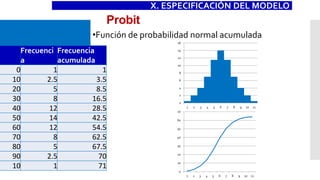
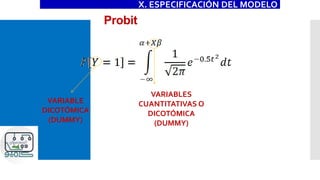


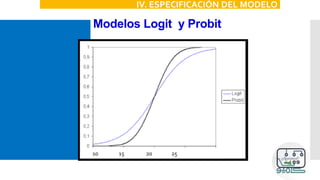
![1. Función de Probabilidad normal
acumulada P[Y=1]=F(X) con F normal acumulada
Consecuencia del no cumplimiento del supuesto: Disminución del ajuste del
modelo.
XII. SUPUESTOS](https://image.slidesharecdn.com/modeloprobit-200221014238/85/Modelos-Logit-y-Probit-con-Stata-53-320.jpg)



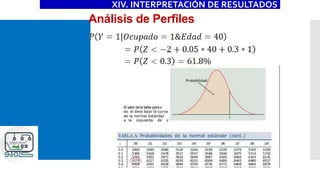
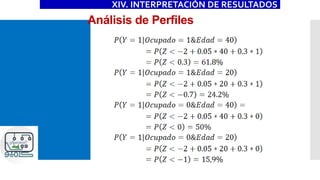



![Ejemplo
XIV. INTERPRETACIÓN DE RESULTADOS
_cons -1.12406 .0091259 -123.17 0.000 -1.141947 -1.106174
ocupa1 .4620657 .0063266 73.04 0.000 .4496658 .4744656
edad .0208241 .0001692 123.07 0.000 .0204925 .0211557
pareja2 Coef. Std. Err. z P>|z| [95% Conf. Interval]
>
ocupa1 .1679902 .0021858 76.86 0.000 .1637061 .1722743
edad .0075709 .0000529 143.23 0.000 .0074673 .0076745
dy/dx Std. Err. z P>|z| [95% Conf. Interval]
Delta-method](https://image.slidesharecdn.com/modeloprobit-200221014238/85/Modelos-Logit-y-Probit-con-Stata-63-320.jpg)



Este documento describe los modelos logit y probit, que son técnicas estadísticas utilizadas para estimar los efectos de variables independientes en una variable dependiente dicotómica. Explica los pasos para especificar, estimar, verificar los supuestos y ajustar estos modelos, así como interpretar los resultados. También compara los modelos logit y probit y cómo se implementan en Stata.















































































