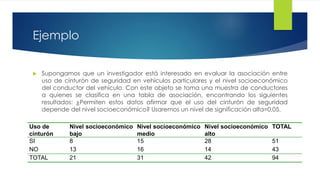
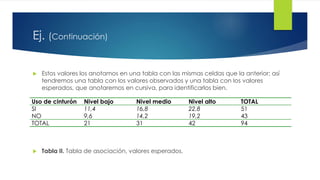
Este documento presenta diferentes pruebas de hipótesis para analizar datos estadísticos, incluyendo pruebas para medias, proporciones, diferencias entre medias y proporciones, y la prueba de chi-cuadrado. También incluye un ejemplo completo de cómo aplicar la prueba de chi-cuadrado para determinar si el uso de cinturón de seguridad depende del nivel socioeconómico usando datos de una muestra.