Descargar para leer sin conexión



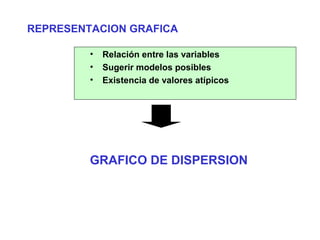



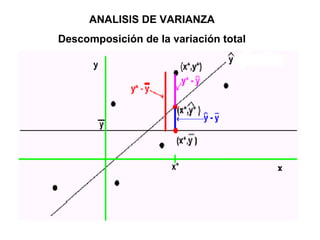




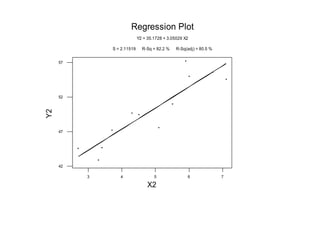
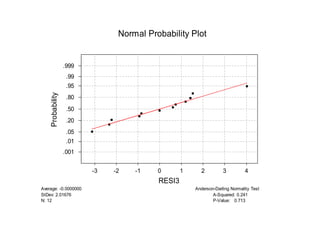
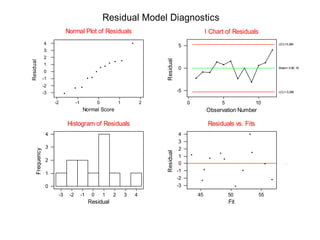
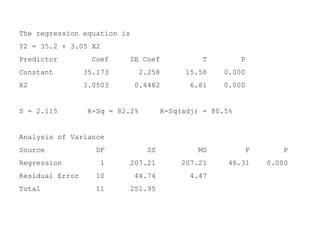








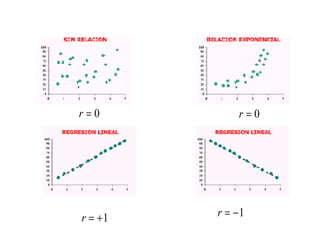

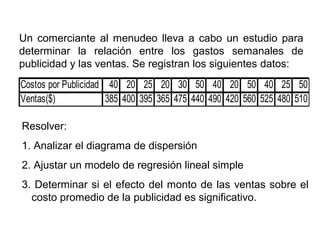

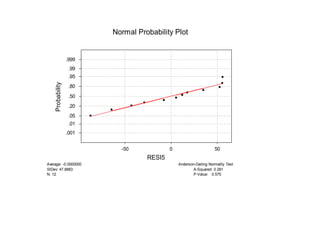
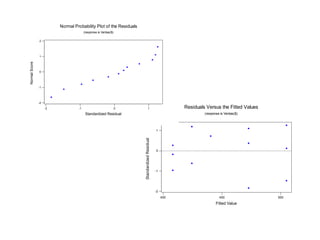

Este documento presenta los objetivos y conceptos clave del análisis de regresión lineal simple. Los objetivos incluyen representar y estimar la recta de regresión, realizar inferencia estadística sobre sus parámetros, y construir intervalos de confianza y predicción. Explica cómo se usa la regresión para predicción, descripción y control de variables. Además, describe los pasos para estimar los parámetros, realizar el análisis de varianza y probar hipótesis sobre los coeficientes y la correlación entre variables.


























































![Bueno de regresion lineal[1]](https://cdn.slidesharecdn.com/ss_thumbnails/buenoderegresionlineal1-100518151837-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)


































