Análisis Estadístico Comunidades España
•Descargar como DOCX, PDF•
0 recomendaciones•60 vistas

Este documento presenta un caso práctico de análisis estadístico de datos demográficos y socioeconómicos de las comunidades de España. Se analizan tres variables: cantidad de habitantes, tasa de desempleo y tasa de delitos. Se realiza un análisis descriptivo completo de cada variable, identificando valores atípicos y comparando la dispersión de las distribuciones. La variable más dispersa es la cantidad de habitantes, mientras que la tasa de delitos tiene la menor dispersión. Finalmente, se ajusta un modelo de regres

Recomendados
Más contenido relacionado
Similar a Análisis Estadístico Comunidades España
Similar a Análisis Estadístico Comunidades España (20)
Último
Último (20)
Análisis Estadístico Comunidades España
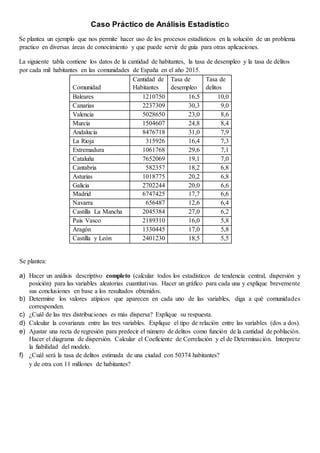
- 1. Caso Práctico de Análisis Estadístico Se plantea un ejemplo que nos permite hacer uso de los procesos estadísticos en la solución de un problema practico en diversas áreas de conocimiento y que puede servir de guía para otras aplicaciones. La siguiente tabla contiene los datos de la cantidad de habitantes, la tasa de desempleo y la tasa de delitos por cada mil habitantes en las comunidades de España en el año 2015. Comunidad Cantidad de Habitantes Tasa de desempleo Tasa de delitos Baleares 1210750 16,5 10,0 Canarias 2237309 30,3 9,0 Valencia 5028650 23,0 8,6 Murcia 1504607 24,8 8,4 Andalucía 8476718 31,0 7,9 La Rioja 315926 16,4 7,3 Extremadura 1061768 29,6 7,1 Cataluña 7652069 19,1 7,0 Cantabria 582357 18,2 6,8 Asturias 1018775 20,2 6,8 Galicia 2702244 20,0 6,6 Madrid 6747425 17,7 6,6 Navarra 656487 12,6 6,4 Castilla La Mancha 2045384 27,0 6,2 País Vasco 2189310 16,0 5,8 Aragón 1330445 17,0 5,8 Castilla y León 2401230 18,5 5,5 Se plantea: a) Hacer un análisis descriptivo completo (calcular todos los estadísticos de tendencia central, dispersión y posición) para las variables aleatorias cuantitativas. Hacer un gráfico para cada una y explique brevemente sus conclusiones en base a los resultados obtenidos. b) Determine los valores atípicos que aparecen en cada uno de las variables, diga a qué comunidades corresponden. c) ¿Cuál de las tres distribuciones es más dispersa? Explique su respuesta. d) Calcular la covarianza entre las tres variables. Explique el tipo de relación entre las variables (dos a dos). e) Ajustar una recta de regresión para predecir el número de delitos como función de la cantidad de población. Hacer el diagrama de dispersión. Calcular el Coeficiente de Correlación y el de Determinación. Interprete la fiabilidad del modelo. f) ¿Cuál será la tasa de delitos estimada de una ciudad con 50374 habitantes? y de otra con 11 millones de habitantes?
- 2. Iniciamos, por el análisis descriptivo completo (calcular todos los estadísticos de tendencia central, dispersión y posición) para las variables aleatorias cuantitativas. Hacer un gráfico para cada una y explique brevemente sus conclusiones en base a los resultados obtenidos. Para el presente trabajo se hace uso del Software IBM SPSS. Para lo cual: Se Configuran las variables. Y se Ingresan los datos: Los datos corresponden a variables de población, tasa de desempleo e índice de delincuencia de distintas comunidades de España. Del análisis preliminar podemos observar que la comunidad con mayor población es Andalucía con 8'476.718 y la de menor población la Rioja con 315.926 habitantes. El mayor índice de desempleo corresponde a Andalucía con 31% y Navarra con el 12,5% el menor. La mayor tasa de desempleo se ubica en Baleares con 10% y el mínimo en Castilla y León.
- 3. A continuación, determinamos los estadísticos de las tres variables. Para lo cual ingresamos por el menú Analizar + Estadísticos descriptivos + Frecuencias. Y configuramos los estadísticos y gráficos de utilidad para el análisis. Los resultados obtenidos, nos presentan los estadísticos de tendencia central, posición y dispersión de las variables cuantitativas: cantidad de habitantes, tasa de desempleo y tasa de delitos. Variable: Cantidad de Habitantes Los valores de tendencia central son: la media de 2'774.203 habitantes, su mediana es 2'045.384 y existen múltiples modas. La amplitud de los datos va desde un valor mínimo de 315.926 habitantes hasta un valor
- 4. máximo de 8´476.718, con un distanciamiento de 8´160.792. Se puede notar un distanciamiento entre la media que se ubica 728.819 unidades a la derecha de la mediana que denota un gran sesgo de la distribución. La distancia promedio de los valores de la distribución es 2'573.589 con respecto a la media. Su asimetría es 1,333 es positiva que denota sesgo a la izquierda, un valor de curtosis de 0,515 que ubica a la distribución como leptocúrtica. CV = (DE/media) *100 = (2'573.589 /2'774.203) *100 ≈ 92,76%, que es mayor al 30%, se puede inferir que la distribución de datos no es normal. Las medidas de posición, nos permite precisar el grado de dispersión de los valores de cada una de las variables, para lo cual la tabla muestra los porcentajes acumulados a partir de los cuales podemos ubicar los cuartiles de la distribución. Cuartiles Q1 = 1'061.768 habitantes; Q2 = 2´045.384 habitantes; Q3 = 2'702.244. Valores determinados en la tabla en columna de frecuencia acumulada en porcentajes (25, 50, 75%) igual o inmediatamente superior. RIQ = Q3 - Q1 = 2'702.244 - 1'061.768 = 1'640.476 Q1: El 25% de la población es menor o igual que 1'061.768 y el otro 75% es mayor que 1'061.768. Q2: El 50% de la población es menor o igual que 2´045.384 habitantes y el otro 50% es mayor que este valor. Q3: El 75% de los encuestados es menor o igual que 2'702.244 y el otro 25% es mayor. El Histograma, nos permite mostrar de mejor manera la distribución de los datos.
- 5. Se puede observar que existe cierto agolpamiento de datos en los valores inferiores y cierta dispersión hacia los superiores. Esta información se confirma con los estadísticos de tendencia central. La media de 2'774.203 habitantes, teniendo en cuenta que la mediana es 2'045.384 vemos que el valor de la media se encuentra bastante desplazada hacia los valores inferiores. Lo que nos permite inferir que esta distribución no es Normal. Variable: tasa de desempleo Los valores de tendencia central son: la media de 21,053 y su mediana es 19,1. Existen múltiples modas. La amplitud de los datos va desde un valor mínimo de 12,6 % hasta un valor máximo de 31% de desempleo, con una amplitud de 18,4 puntos. Se puede notar un distanciamiento entre la media que se ubica 2 unidades a la derecha de la mediana que denota un cierto sesgo de la distribución. La desviación típica de los valores de la distribución es con respecto a la media es de 5,58 puntos. Su asimetría es 0,648 es positiva que denota sesgo a la izquierda, un valor de curtosis de -0,736 que ubica a la distribución como planticúrtica. CV = (DE/media) *100 = (5,58/21.053) *100 ≈ 26,5%, que es menor al 30%, se puede inferir que la distribución de datos puede ser normal. (lo que se puede confirmar con las pruebas de normalidad) Las medidas de posición, se determinan a partir de los valores del porcentaje acumulado.
- 6. Cuartiles Q1 = 17%; Q2 =19,1%; Q3 =24,8%. Valores determinados en la tabla en columna de frecuencia acumulada en porcentajes (25, 50, 75%) igual o inmediatamente superior. Q1: El 25% de la tasa de desempleo es menor o igual que 17 y el otro 75% es mayor que 17. Q2: El 50% de la tasa de desempleo es menor o igual que 19,1 y el otro 50% es mayor. Q3: El 75% de la tasa de desempleo es menor o igual que 24,8 y el otro 25% es mayor. El Histograma, nos permite confirmar los resultados obtenidos.
- 7. Se puede observar cierta concentración de datos a la izquierda y cierta dispersión hacia los superiores. En otras palabras, la tasa de desempleo se concentra entre 15 y 25 %. Esta información se confirma con los estadísticos de tendencia central. Donde la media obtenida es de 21,053%, teniendo en cuenta que la mediana es 19,1% vemos que el valor de la media se encuentra ligeramente desplazada hacia los valores inferiores. Variable: tasa de delito La media obtenida es de 7,165% y su mediana es 6,8%. Existen múltiples modas. La amplitud de los datos va desde un valor mínimo de 5,5 % hasta un valor máximo de 10% de desempleo, con un rango de 4,5 puntos. Se puede notar un distanciamiento entre la media que se ubica 0,365 unidades a la derecha de la mediana que denota un cierto leve sesgo de la distribución. La desviación típica de los valores de la distribución es con respecto a la media es de 1,24 puntos. Su asimetría es 0,849 es positiva que denota sesgo a la izquierda, un valor de curtosis de 0,185 que ubica a la distribución como leptocúrtica. CV = (DE/media) *100 = (1,24/7,165) *100 ≈ 0,17%, que es menor al 30%, se puede inferir que la distribución de datos podría ser normal. (lo que se puede confirmar con las pruebas de normalidad) Los Cuartiles obtenidos son: Q1 = 6,4%; Q2 =6,8%; Q3 =7,9%. Siendo la variable donde se observa una menor dispersión de los valores tanto en amplitud como en cuanto a los valores centrales. El Histograma, nos permite confirmar los resultados obtenidos.
- 8. ANALISIS EXPLORATORIO Determine los valores atípicos que aparecen en cada uno de las variables, diga a qué comunidades corresponden. Los valores atípicos son aquellos que muestran una gran distancia a la media del resto de puntuaciones en la variable. Para su determinación, los valores atípicos son aquellos que se sitúan fuera del siguiente intervalo: Límite inferior = Q1 - 1.5*RIQ; Límite superior = Q3 +1.5*RIQ. Variable: Cantidad de Habitantes Límite inferior = 1'061.768 - 1.5*(1'640.476) = 1'061.768 - 2'460.714 = -1'398946, como no existen cantidad de habitantes negativas, podemos concluir que no existen valores atípicos a la izquierda. Límite superior = 2'702.244 + 2'460.714 = 5'162.958, por lo tanto, los valores del dato 13 (Andalucía = 8'476.718), dato 10 (Cataluña = 7'652.069), dato 6 (Madrid = 6´747.425) son valores atípicos a la derecha, pues se ubican por encima del límite. Variable: tasa de desempleo Límite inferior = 17 - 1.5*(7,8) = 17 - 11,7 = 5,3, y su límite superior = 24,8 + 11.7 = 36,5, como todos los valores están dentro del intervalo, podemos inferir que esta variable no posee valores atípicos. Variable: tasa de delitos Límite inferior = 6,4 - 1.5*(1,5) = 6,4 - 2,25 = 4,15, y su límite superior = 7,9 + 2,25 = 10,15, se tiene que los valores están dentro del intervalo, podemos deducir que esta variable no posee valores atípicos. La existencia de datos atípicos como los determinados en la variable cantidad de habitantes, afecta los resultados de estadísticos como media, desviación, correlación, regresión por esas razones es recomendable darles el mejor tratamiento posible a estos datos. Una posibilidad es replicar el análisis con y sin dichas observaciones con el fin de analizar su influencia sobre los resultados y reportarlos en las conclusiones. Otra alternativa es el uso de métodos robustos que no se vean afectados por estos valores o que disminuyan su
- 9. afectación. Y finalmente no modificarlos pues son parte de la muestra y hacer uso de métodos no paramétricos para su análisis. ¿Cuál de las tres distribuciones es más dispersa? Explique su respuesta. Para este análisis, usaremos ciertas medidas de dispersión y de posición que me permitirán precisar la intensidad y dirección de la dispersión de los datos de las tres variables. Rango 8160792 18,4 4,5 Desv. Desviación 2573589,307 5,5792 1,2374 Media 2774203,18 21,053 7,165 Variable: Cantidad de habitantes Se puede observar que existen valores atípicos que corresponden a las comunidades de Andalucía, Cataluña y Madrid. La amplitud de los datos es de 8´160.792 habitantes que nos indica gran dispersión con respecto a los valores extremos, su rango intercuartil es de 1'640.476 habitantes que nos indica la concentración del 50% de los valores centrales, se puede notar que la caja del diagrama se acerca más a los valores inferiores (donde se observa una mayor concentración de valores) y el valor de la mediana es cercana al cuartil tres. Del análisis se infiere que los valores se concentran a la izquierda, lo que reafirma la asimetría positiva. Si se compara con las otras variables, los resultados de esta variable muestran una mayor dispersión que lo evidencia su valor de desviación típica y las medidas de posición advierten de la posibilidad de que su distribución no sea Normal (Razón por la cual los métodos a utilizarse para su análisis podrían ser no paramétricos). Variable: Tasa de desempleo
- 10. A diferencia de la anterior la caja del diagrama anterior, está se ubica más centrada, aunque el valor de la mediana se sesga hacia el primer cuartil donde se tiene una mayor concentración con respecto a la mediana y el tercer cuartil donde hay más dispersión. Se puede observar que no existen valores atípicos, el rango es de 18.4 que nos indica poca dispersión con respecto a los valores extremos, su rango intercuartil es de 7,8 que nos indica la concentración del 50% de los valores centrales (17% a 24,8%), se puede notar que la caja del diagrama se acerca más al valor inferior donde se observa una mayor concentración de valores. Algo similar es el análisis de posición de la mediana de 19,1 y el valor del primer cuartil de 17 tiene mayor concentración en comparación con la mediana y el tercer cuartil de 24,8 donde es mayor la dispersión de valores. Del análisis se infiere que los valores se concentran a la izquierda, lo que reafirma la asimetría positiva. Su desviación típica es 5,57 puntos, que evidencia poca dispersión de sus datos. La tasa de delitos tampoco tiene valores atípicos, su rango es 4,5 unidades que nos indica poca dispersión con respecto a los valores extremos, su rango intercuartil es de 1,5 unidades que nos indica la concentración del 50% de los valores centrales (6,4 a 7,9), se puede notar que la caja del diagrama se acerca más al valor menor donde se observa una mayor concentración de valores. Algo similar al análisis de posición de la mediana (6,8 unidades porcentuales) y el valor del primer cuartil de 6,4 tiene mayor concentración en comparación con la mediana y el tercer cuartil de 7,9 donde se observa mayor dispersion. Del análisis se infiere que los valores se
- 11. concentran a la izquierda, lo que reafirma la asimetría positiva. Su desviación típica es 1,24 puntos porcentuales, que evidencia que es la variable de menor dispersión. Calcular la covarianza entre las tres variables. Explique el tipo de relación entre las variables (dos a dos). Si tomamos todos los valores incluyendo a los atípicos, los resultados obtenidos son: Estadísticos descriptivos Media Desv. Desviación N Cantidad de habitantes 2774203,18 2573589,307 17 Tasa de desempleo 21,053 5,5792 17 Tasa de delitos 7,165 1,2374 17 Correlaciones Cantidad de habitantes Tasa de desempleo Tasa de delitos Cantidad de habitantes Correlación de Pearson 1 ,277 ,086 Sig. (bilateral) ,282 ,744 Suma de cuadrados y productos vectoriales 10597379075 0628,470 63614858,64 1 4365545,306 Covarianza 66233619219 14,279 3975928,665 272846,582 N 17 17 17 Tasa de desempleo Correlación de Pearson ,277 1 ,355 Sig. (bilateral) ,282 ,162 Suma de cuadrados y productos vectoriales 63614858,64 1 498,042 39,182 Covarianza 3975928,665 31,128 2,449 N 17 17 17 Tasa de delitos Correlación de Pearson ,086 ,355 1 Sig. (bilateral) ,744 ,162 Suma de cuadrados y productos vectoriales 4365545,306 39,182 24,499 Covarianza 272846,582 2,449 1,531 N 17 17 17 Los valores obtenidos, se traducen en correlaciones positivas de intensidad débil. Es decir, los valores de correlación no justificarían un análisis de regresión.
- 12. Ajustar una recta de regresión para predecir el número de delitos como función de la cantidad de población. Hacer el diagrama de dispersión. Calcular el Coeficiente de Correlación y el de Determinación. Interprete la fiabilidad del modelo. Se procede a graficar el diagrama de dispersión de tasa de delitos = f(cantidad de habitantes): Su gráfica, muestra una correlación bastante débil pues los valores inferiores se distancian de la recta, lo haría difícil justificar la elaboración de un modelo de regresión lineal. Resumen del modelo Modelo R R cuadrado R cuadrado ajustado Error estándar de la estimación 1 ,086a ,007 -,059 1,2733 a. Predictores: (Constante), Cantidad de habitantes El coeficiente de correlación es casi nulo R=0.086 y el de determinación R2 = 0.007. Resultados que evidencian que no se justifica un análisis de regresión con valores tan pequeños. ANOVAa Modelo Suma de cuadrados gl Media cuadrática F Sig. 1 Regresión ,180 1 ,180 ,111 ,744b Residuo 24,319 15 1,621 Total 24,499 16 a. Variable dependiente: Tasa de delitos b. Predictores: (Constante), Cantidad de habitantes
- 13. Coeficientesa Modelo Coeficientes no estandarizados Coeficientes estandarizado s t Sig. B Desv. Error Beta 1 (Constante) 7,050 ,462 15,273 ,000 Cantidad de habitantes 4,119E-8 ,000 ,086 ,333 ,744 a. Variable dependiente: Tasa de delitos ¿Cuál será la tasa de delitos estimada de una ciudad con 50374 habitantes? y de otra con 11 millones de habitantes? Y = 0.00000004X + 7,0504 = 0.00000004(503749) + 7,0504= Y = 0.00000004(11000000) + 7,0504= 7,49