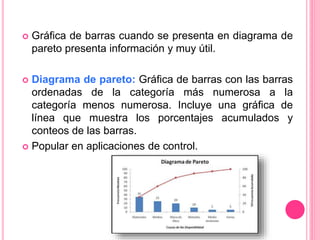
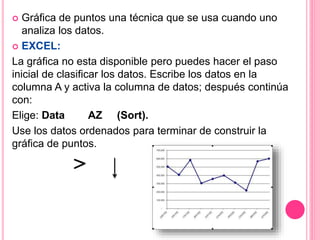
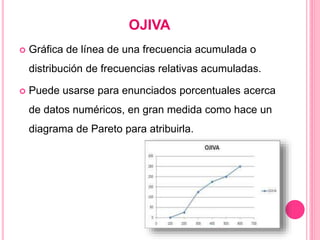
Este documento describe diferentes tipos de gráficas y diagramas que pueden usarse para resumir datos cualitativos y cuantitativos, incluyendo gráficas de pastel, de barras, diagramas de Pareto, gráficas de puntos, distribuciones de frecuencias e histogramas. También explica medidas como la media, mediana, moda, varianza y desviación estándar que resumen conjuntos de datos.