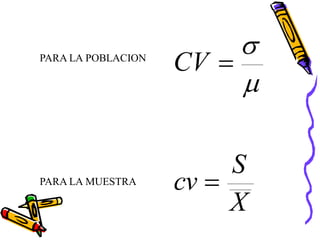
Este documento describe diferentes medidas descriptivas para condensar y describir datos, incluyendo medidas de tendencia central (media, mediana y moda), medidas de dispersión (rango, desviación típica y varianza) y medidas de asimetría y forma (sesgo, curtosis y simetría). Explica que las medidas de tendencia central proporcionan un solo valor para representar los datos centrales, mientras que las medidas de dispersión miden qué tan extendidos están los datos y las medidas de asimetría y forma describen la forma de la curva de distribución.


































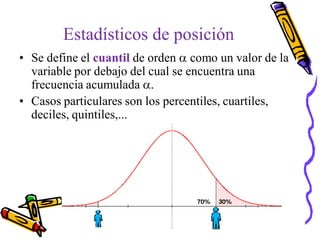






![Fórmula General para los Cuantiles
Datos Agrupados
Me = LRI + [( k(n+1)/p – faca)/ fmp] * Cr
LRI: límite real inferior del cuantil
n: frecuencia total
faca: frecuencia acumulada anterior al intervalo donde está localizado
el cuantil
fmp: frecuencia del intervalo donde está localizado el cuantil
Cr: ancho real del intervalo
Si se desean calcular los cuartiles p =4
Si se desea calcular los deciles p= 10
Si se desea calcular los percentiles p= 100](https://image.slidesharecdn.com/modulo5medidasdescriptivas-120516135222-phpapp01/85/Modulo-5-medidas-descriptivas-42-320.jpg)