
Descargar como PDF, PPTX


































![Ejemplo 5:
Suponiendo un 20% de enfermedad en el grupo de No Expuestos en un
estudio de cohortes, ¿Cuál es el tamaño mínimo que necesitamos en cada
grupo de Expuestos/No Expuestos para estimar el RR en expuestos con un
10% del valor real, pensando que es aproximadamente de 1,75, con un 95%
de confianza?
Con los datos observamos que
P2=0,2
Como RR=(a/n1)/(b/n2); a/n1=p1 y b/n2=p2
Entonces, P1=(RR)P2 = 0,2*1,75 = 0,35
1,962 [(0,65 / 0,35) (0,8 / 0,2)]
Y N 2026,95
[ln(1 0,1)]2
Si quisiéramos tener un nivel de confianza del 99%
2,5762 [(0,65 / 0,35) (0,8 / 0,2)]
N 3501,24
[ln(1 0,1)]2](https://image.slidesharecdn.com/muestraymuestreo-120121174730-phpapp02/85/Muestra-y-muestreo-36-320.jpg)
![Ejemplo 6:
Suponiendo un 15% de enfermedad en el grupo de No Expuestos y una
diferencia máxima del 30% con el grupo de expuestos en un estudio de
cohortes, ¿Cuál es el tamaño mínimo que necesitamos en cada grupo de
Expuesto/No Expuestos para estimar el RR sobre un 20% del valor real, con
un 95% de confianza?
Con los datos observamos que
P1=0,45 1,962 [(0,55 / 0,45) (0,85 / 0,15)]
N 531,48
P2=0,15 [ln(1 0,2)]2
Si quisiéramos asumir solo un 10% de variabilidad sobre el valor real.
1,962 [(0,60 / 0,40) (0,85 / 0,15)]
N 2383,99
[ln(1 0,1)]2](https://image.slidesharecdn.com/muestraymuestreo-120121174730-phpapp02/85/Muestra-y-muestreo-37-320.jpg)
![Ejemplo 8:
Se realiza un estudio multicéntrico para evaluar el efecto de un fármaco sobre
una patología concreta cardiovascular. Los pacientes serán randomizados en
dos Brazos (A y B). Calcular el número de pacientes que debe haber en cada
brazo para un poder del 90% y un nivel de confianza del 95%, con un diseño
de dos colas, asumiendo como peor prevalencia en Brazo B 0,35 y asumiendo
un RR=2.
Con los datos observamos que
P2=0,35 P1=(RR)P2=0.7 P=P1+P2/2=0.525
Sustituyendo en la fórmula
N
1,96
[2(0,525)(0,475) 1.282 [(0,7)(0,3) (0,35)(0,65)]
2
40,67
(0,7 0,35) 2
Si quisiéramos tener un nivel de confianza del 99% y un poder del 80%:
N
2,576 [2(0,525)(0,475) 0,842 [(0,7)(0,3) (0,35)(0,65)]
2
46,09
(0,7 0,35) 2](https://image.slidesharecdn.com/muestraymuestreo-120121174730-phpapp02/85/Muestra-y-muestreo-38-320.jpg)
![Ejemplo 9:
Aceptando un 15% de enfermedad en el grupo de No Expuestos y una
diferencia máxima del 30% con el grupo de expuestos en un estudio de
cohortes, ¿Cuál es el tamaño mínimo que necesitamos en cada grupo de
Expuesto/No Expuestos para estimar el RR con un error tipo II del 20% y con
un 95% de confianza?
Con los datos observamos que
P1=0,45
P2=0,15
N
1,96
2
[2(0,525)(0,475) 0,842 [(0,7)(0,3) (0,35)(0,65)]
35,44
(0,7 0,35) 2
Si quisiéramos asumir un poder del 90%.
N
1,96
[2(0,525)(0,475) 1.282 [(0,7)(0,3) (0,35)(0,65)]
2
46,94
(0,7 0,35) 2](https://image.slidesharecdn.com/muestraymuestreo-120121174730-phpapp02/85/Muestra-y-muestreo-39-320.jpg)


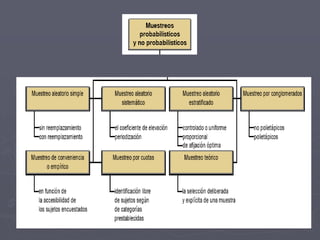















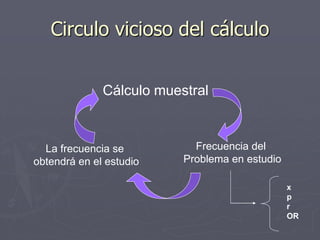
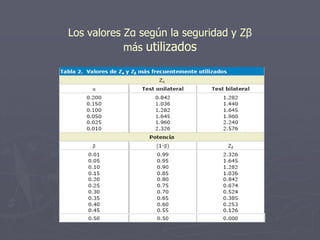
Este documento presenta conceptos básicos sobre cálculos muestrales como población, muestra, parámetro, estadístico, varianza poblacional, inferencia estadística, error muestral y nivel de confianza. Luego explica fórmulas para calcular el tamaño de muestra para estimar la media, proporción y correlación de una población, así como para estudios de casos y controles y cohortes. Finalmente incluye ejemplos numéricos de cálculos de tamaño muestral.











































































































