
Descargado 57 veces




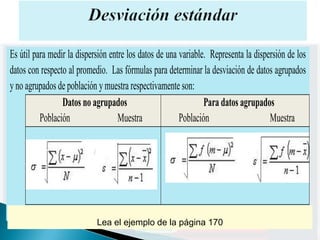




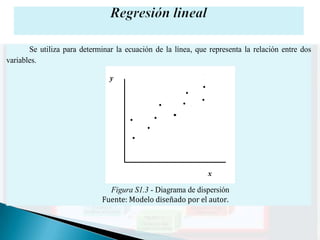

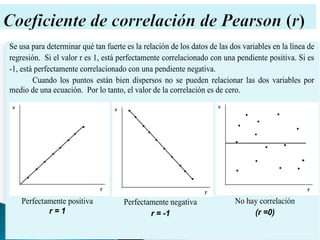
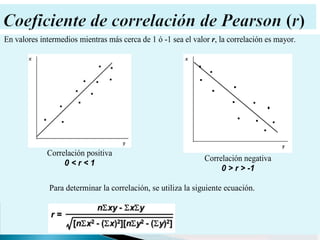










El documento proporciona una guía sobre estadística paramétrica y no paramétrica, incluyendo pruebas y computos como promedios, desviaciones estándar, regresión lineal y análisis de varianza. Explica cómo determinar la normalidad de los datos, medidas de tendencia central, y la comparación de grupos mediante diversas pruebas estadísticas. También se incluyen ejemplos prácticos y enlaces para obtener más información y ejercicios adicionales.






























































































