Descargar como PDF, PPTX



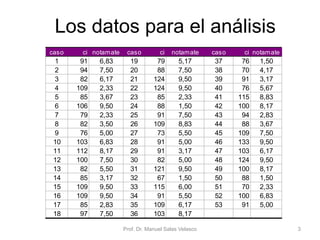


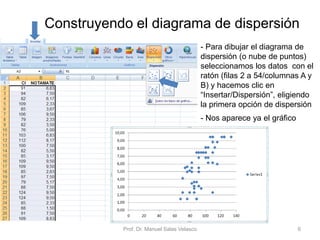
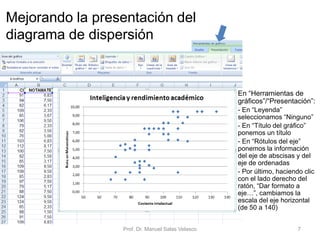


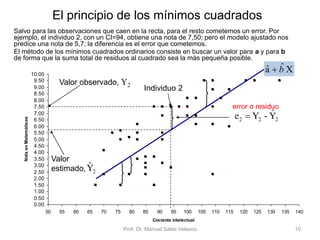
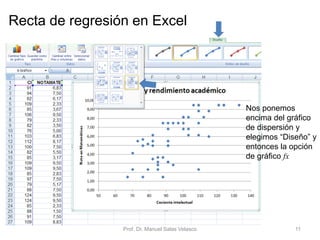
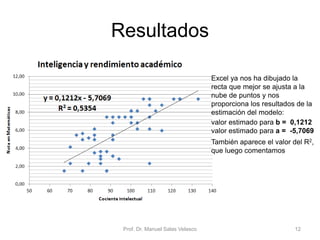

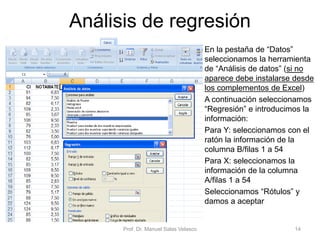




El documento presenta un análisis de regresión utilizando datos del rendimiento académico de estudiantes de primaria en relación con su cociente intelectual. Se busca determinar si un mayor CI se asocia a mejores notas en matemáticas, utilizando Excel para graficar y ajustar una recta de regresión mínima cuadrática. Se concluye que el CI explica un 53,5% de la variación en las notas, permitiendo hacer predicciones sobre el rendimiento escolar.