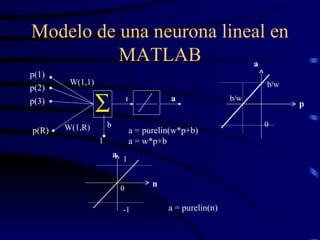
El documento resume los conceptos clave de las redes neuronales ADALINE (Adaptive Linear Neuron) y el algoritmo LMS (Least Mean Square). La red ADALINE es similar al perceptrón pero con una función de transferencia lineal en lugar de una función escalón. El algoritmo LMS minimiza el error cuadrático medio y es más poderoso que la regla de aprendizaje del perceptrón para resolver problemas de clasificación linealmente separables.













![INICIALIZACIÓN Y DISEÑO La función initlin es usada para inicializar los pesos y los bias de la capa lineal con valores positivos y negativos. [W,b]=initlin(P,T) Las redes lineales pueden ser diseñadas directamente si se conocen sus vectores de entrada y objetivo por medio de la función solvelin, la cual encuentra los valores de los pesos y el bias sin necesidad de entrenamiento . [W,b]=solvelin(P,T); W=solvelin(P,T);](https://image.slidesharecdn.com/redneuronaladaline-091022213842-phpapp01/85/Red-Neuronal-Adaline-15-320.jpg)









![ENTRENAMIENTO ADALINE Por medio de Matlab, se puede realizar el entrenamiento por medio de learnwh, realizando las funciones siguientes: A = simulin (P,W,b) E = T - A [dW,db] = learnwh (P,E,lr) W = W + dW b = b + dW](https://image.slidesharecdn.com/redneuronaladaline-091022213842-phpapp01/85/Red-Neuronal-Adaline-25-320.jpg)
![En MATLAB: E = T - A; [ dW, db ] = learnwh( P, E, lr ) lr es la tasa de aprendizaje . Si es grande, el aprendizaje es rápido, pero si es demasiado grande, el aprendizaje es inestable y puede incrementarse el error. lr = maxlinlr( P ); % si no se utiliza bias lr = maxlinlr( P, ‘bias’ ); %si se utiliza bias W = W + dW; b = b + db;](https://image.slidesharecdn.com/redneuronaladaline-091022213842-phpapp01/85/Red-Neuronal-Adaline-26-320.jpg)


![ENTRENAMIENTO ADALINE La sintaxis de la función es: tp = [disp_frec max_epoch err_goal lr ] [W,b,ep,tr] = trainwh(W,b,P,T,tp) tp es un parámetro que indica la frecuencia de progreso en el entrenamiento, el máximo de repeticiones, el error mínimo permisible y la tasa de aprendizaje (ver Aprendizaje) y puede contener valores nulos o NAN. La función regresa los pesos W, los umbrales b, el número de repeticiones usado ep y un registro del error de entrenamiento tr](https://image.slidesharecdn.com/redneuronaladaline-091022213842-phpapp01/85/Red-Neuronal-Adaline-29-320.jpg)


























































