Descargar como PDF, PPTX






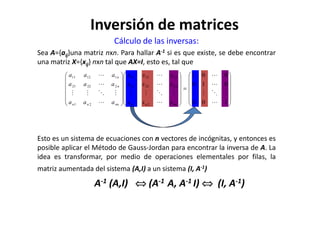






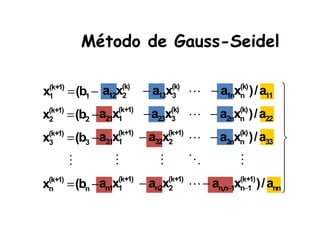





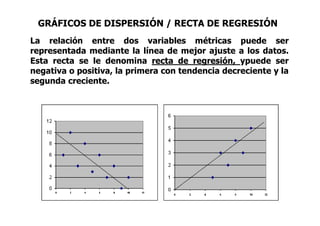
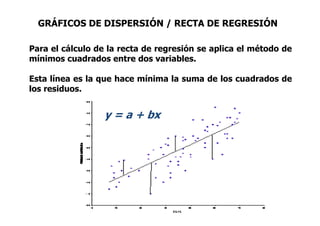
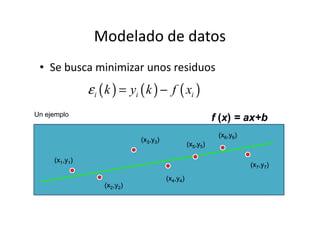
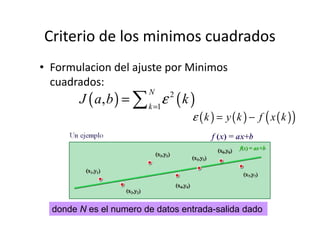



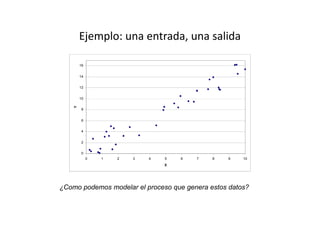
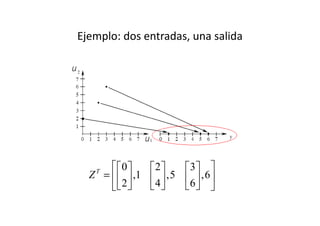






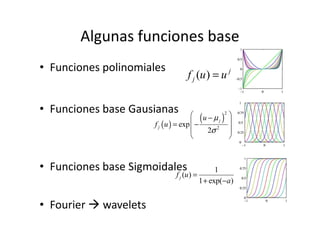
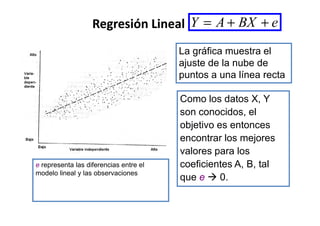
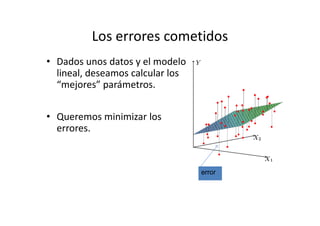
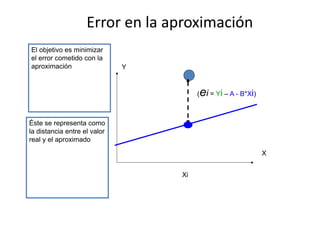


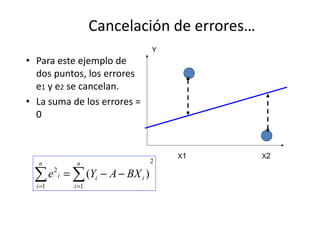





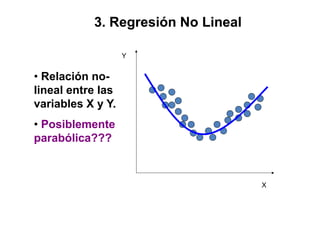



Este documento describe diferentes métodos matemáticos como la inversión de matrices, sistemas de ecuaciones lineales y mínimos cuadrados. Explica cómo calcular la inversa de una matriz y las propiedades de la inversión matricial. También cubre métodos para resolver sistemas de ecuaciones lineales como los métodos de Jacobi y Gauss-Seidel. Finalmente, introduce el concepto de ajuste de curvas por mínimos cuadrados para modelar datos experimentales.











































































































