Descargado 12 veces





![4.1.2 RANGO INTERCUARTÍLICO (RIQ).4.1.2 RANGO INTERCUARTÍLICO (RIQ).
• Lo calculamos como la diferencia entre el
tercero y el primero de los cuartiles.
• RIQ = q3 - q1, el intervalo [q1,q3] contiene al
50% central de los valores muestrales.](https://image.slidesharecdn.com/estadsticayprobabilidadescapiv-130927142906-phpapp02/85/Estadistica-y-probabilidades-cap-IV-5-320.jpg)





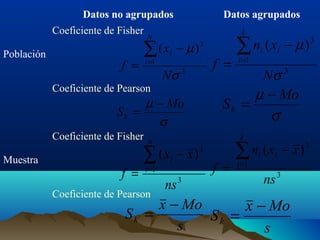
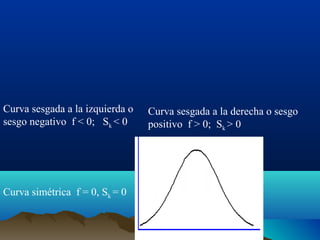

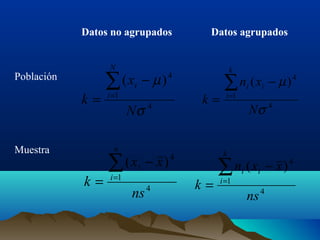
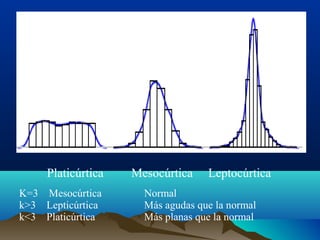

Este documento trata sobre medidas de dispersión y forma en estadística. Explica medidas de dispersión como el rango, rango intercuartílico, desviación media y varianza. También cubre medidas de forma como asimetría y curtosis. Define cada medida y proporciona fórmulas para calcularlas tanto para datos agrupados como no agrupados.











































































































