Alfabeto Griego, Símbolos Matemáticos y Estadística
•
0 recomendaciones•1,977 vistas

Formulario de Estadística dirigido a tanto a jóvenes de bachillerato en México, como a estudiantes de Nivel Superior de todas las carreras que le requieran, como por ejemplo Ingeniería, Pedagogía, Psicología, etc. Contempla los temas fundamentales.

Recomendados
Recomendados
Más contenido relacionado
La actualidad más candente
La actualidad más candente (20)
Similar a Alfabeto Griego, Símbolos Matemáticos y Estadística
Similar a Alfabeto Griego, Símbolos Matemáticos y Estadística (20)
Más de Gerardo Ignacio Bonilla Alfonso
Más de Gerardo Ignacio Bonilla Alfonso (12)
Último
Último (20)
Alfabeto Griego, Símbolos Matemáticos y Estadística
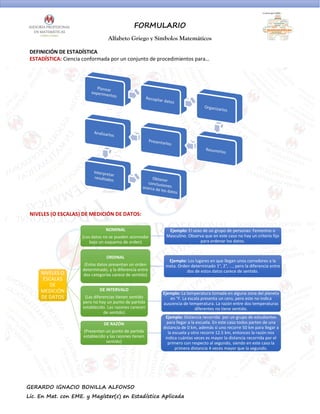
- 1. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada DEFINICIÓN DE ESTADÍSTICA ESTADÍSTICA: Ciencia conformada por un conjunto de procedimientos para… NIVELES (O ESCALAS) DE MEDICIÓN DE DATOS: NIVELES O ESCALAS DE MEDICIÓN DE DATOS NOMINAL (Los datos no se pueden acomodar bajo un esquema de orden) Ejemplo: El sexo de un grupo de personas: Femenino o Masculino. Observa que en este caso no hay un criterio fijo para ordenar los datos. ORDINAL (Estos datos presentan un orden determinado, y la diferencia entre dos categorías carece de sentido) Ejemplo: Los lugares en que llegan unos corredores a la meta. Orden determinado 1°, 2°, ..., pero la diferencia entre dos de estos datos carece de sentido. DE INTERVALO (Las diferencias tienen sentido pero no hay un punto de partida establecido. Las razones carecen de sentido) Ejemplo: La temperatura tomada en alguna zona del planeta en °F. La escala presenta un cero, pero este no indica auscencia de temperatura. La razón entre dos temperaturas diferentes no tiene sentido. DE RAZÓN (Presentan un punto de partida establecido y las razones tienen sentido) Ejemplo: Distancia recorrida por un grupo de estudiantes para llegar a la escuela. En este caso todos parten de una distancia de 0 km, además si uno recorre 50 km para llegar a la escuela y otro recorre 12.5 km, entonces la razón nos indica cuántas veces es mayor la distancia recorrida por el primero con respecto al segundo, siendo en este caso la primera distancia 4 veces mayor que la segundo.
- 2. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada MEDIDAS DE TENDENCIA CENTRAL Datos no agrupados Datos agrupados Media Aritmética Poblacional 𝝁 𝜇 = ∑ 𝑥 𝑁 = ∑ 𝑓 𝑥 𝑁 𝑥 : i-ésimo dato 𝑓 : Frecuencia absoluta del i-ésimo dato 𝑁: Número de datos 𝑘: Número de datos diferentes 𝜇 = ∑ 𝑓 𝑚 𝑁 𝑚 : i-ésima marca de clase 𝑓 : Frecuencia de clase del i-ésimo intervalo de clase 𝑁: Número de datos 𝑘: Número de intervalos de clase Muestral 𝑥 𝑥 = ∑ 𝑥 𝑁 = ∑ 𝑓 𝑥 𝑁 𝑥 : i-ésimo dato 𝑓 : Frecuencia absoluta del i-ésimo dato 𝑁: Número de datos 𝑘: Número de datos diferentes 𝑥 = ∑ 𝑓 𝑚 𝑁 𝑚 : i-ésima marca de clase 𝑓 : Frecuencia de clase del i-ésimo intervalo de clase 𝑁: Número de datos 𝑘: Número de intervalos de clase Mediana * Se deben ordenar los datos en forma ascendente. a) Si 𝑁 (el número de datos) es impar, la mediana 𝑀𝑒 será el dato que se encuentra a la mitad de todos. b) Si 𝑁 (el número de datos) es par, la mediana 𝑀𝑒 será el promedio de los dos datos que se localizan a la mitad de todos. 𝑀𝑒 = 𝐿 + 𝑁 2 − (∑ 𝑓) 𝑓 𝑐 𝐿: Extremo inferior (real) de la clase que contiene a la mediana (∑ 𝑓): Suma de las frecuencias de las clases inferiores a la clase que contiene a la mediana 𝑁: Número de datos 𝑐: Tamaño (real) del intervalo de clase que contiene a la mediana 𝑓 : Frecuencia de la clase que contiene a la mediana Nota: Para determinar el lugar donde se ubica la mediana, se usa la regla . Moda La moda (Mo) es el dato con mayor frecuencia absoluta. 𝑀𝑜 = 𝐿 + 𝛥 𝛥 + 𝛥 𝑐 𝐿: Extremo inferior real de la clase modal 𝛥 : Diferencia de la frecuencia modal con la frecuencia de la clase inferior inmediata 𝛥 : Diferencia de la frecuencia modal con la frecuencia de la clase superior inmediata 𝑐: Tamaño (real) del intervalo de la clase modal Datos no agrupados Media Geométrica 𝑮 𝐺 = 𝑥 = 𝑥 ⋅ 𝑥 ⋅⋅⋅ 𝑥 𝑥 : i-ésimo dato (debe ser positivo) 𝑁: Número de datos Nota: En el área administrativa (negocios y economía) se emplea para determinar las tasas de cambio promedio, las tasas de crecimiento promedio o tasas promedio.
- 3. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada Media Armónica 𝑯 𝐻 = 1 1 𝑁 ∑ 1 𝑥 = 𝑁 ∑ 1 𝑥 𝑥 : i-ésimo dato (todos los datos deben ser diferentes de cero) 𝑁: Número de datos Nota: Se emplea usualmente como medida de tendencia central para datos consistentes en tasas de cambio. Relación entre la media aritmética, la media geométrica y la media armónica 𝐻 ≤ 𝐺 ≤ 𝑥 Reglas para determinar el número de clases 𝒌 a considerar, con base en el número de datos de una muestra Regla de la Raíz cuadrada 𝑘 = √𝑁 𝑁: Número de datos NOTA: 𝒌 se debe aproximar al menor entero mayor o igual que el valor de 𝒌 obtenido directamente de la fórmula. Regla de Sturges 𝑘 = 1 + 3.322 𝑙𝑜𝑔 𝑁 𝑁: Número de datos NOTA: El valor de k se debe redondear de la siguiente forma: Si el entero del resultado obtenido directamente de la fórmula es "par", se redondea al entero siguiente más próximo. Si el entero del resultado obtenido directamente de la fórmula es "impar", se redondea al entero menor o igual que 𝒌. NOTA: El número de clases no debe ser menor a 5 ni mayor de 20. Longitud del Intervalo de Clase 𝑐 = 𝑅𝑎𝑛𝑔𝑜 𝑁𝑜. 𝑑𝑒 𝑐𝑙𝑎𝑠𝑒𝑠 𝑛𝑒𝑐𝑒𝑠𝑎𝑟𝑖𝑜 El resultado se debe redondear a un número conveniente, un poco mayor que el valor de 𝑐 obtenido de fórmula. Si tus datos son enteros, se sugiere considerar al entero siguiente más próximo al valor de 𝑐 obtenido directamente de la fórmula. MEDIDAS DE DISPERSIÓN Rango 𝑅𝑎𝑛𝑔𝑜 = 𝑥 − 𝑥 𝑥 : Dato mayor (N-ésimo dato) 𝑥 : Dato menor (primer dato) Datos no agrupados Datos agrupados Desviación Media (o Promedio de Desviaciones) Poblacional DM 𝐷𝑀 = ∑ |𝑥 − 𝜇| 𝑁 = ∑ 𝑓 |𝑥 − 𝜇| 𝑁 𝑥 : i-ésimo dato 𝜇: Media aritmética de los datos 𝑓 : Frecuencia absoluta del i-ésimo dato 𝑁: Número de datos 𝑘: Número de datos diferentes 𝐷𝑀 = ∑ 𝑓 |𝑚 − 𝜇| 𝑁 𝑚 : i-ésima marca de clase 𝜇: Media aritmética de los datos 𝑓 : Frecuencia de clase del i-ésimo intervalo de clase 𝑁: Número de datos 𝑘: Número de intervalos de clase Muestral DM 𝐷𝑀 = ∑ |𝑥 − 𝑥| 𝑁 = ∑ 𝑓 |𝑥 − 𝑥| 𝑁 𝑥 : i-ésimo dato 𝑥: Media aritmética de los datos 𝑓 : Frecuencia absoluta del i-ésimo dato 𝑁: Número de datos 𝑘: Número de datos diferentes 𝐷𝑀 = ∑ 𝑓 |𝑚 − 𝑥| 𝑁 𝑚 : i-ésima marca de clase 𝑥: Media aritmética de los datos 𝑓 : Frecuencia de clase del i-ésimo intervalo de clase 𝑁: Número de datos 𝑘: Número de intervalos de clase
- 4. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada Datos no agrupados Datos agrupados Varianza Poblacional 𝝈𝟐 𝜎 = ∑ (𝑥 − 𝜇) 𝑁 = ∑ 𝑓 (𝑥 − 𝜇) 𝑁 𝑥 : i-ésimo dato 𝜇: Media aritmética de los datos 𝑓 : Frecuencia absoluta del i-ésimo dato 𝑁: Número de datos 𝑘: Número de datos diferentes 𝜎 = ∑ 𝑓 (𝑚 − 𝜇) 𝑁 𝑚 : i-ésima marca de clase 𝜇: Media aritmética de los datos 𝑓 : Frecuencia de clase del i-ésimo intervalo de clase 𝑁: Número de datos 𝑘: Número de intervalos de clase Muestral 𝑺𝟐 𝑆 = ∑ (𝑥 − 𝑥) 𝑁 − 1 = ∑ 𝑓 (𝑥 − 𝑥) 𝑁 − 1 𝑥 : i-ésimo dato 𝑥: Media aritmética de los datos 𝑓 : Frecuencia absoluta del i-ésimo dato 𝑁: Número de datos 𝑘: Número de datos diferentes 𝑆 = ∑ 𝑓 (𝑚 − 𝑥) 𝑁 − 1 𝑚 : i-ésima marca de clase 𝑥: Media aritmética de los datos 𝑓 : Frecuencia de clase del i-ésimo intervalo de clase 𝑁: Número de datos 𝑘: Número de intervalos de clase Datos no agrupados Datos agrupados Desviación Estándar (o típica) Poblacional 𝝈 𝜎 = ∑ (𝑥 − 𝜇) 𝑁 = 𝜎 𝑥 : i-ésimo dato 𝜇: Media aritmética de los datos 𝑁: Número de datos 𝜎 = ∑ 𝑓 (𝑚 − 𝜇) 𝑁 = 𝜎 𝑚 : i-ésima marca de clase 𝜇: Media aritmética de los datos 𝑓 : Frecuencia de clase del i-ésimo intervalo de clase 𝑁: Número de datos 𝑘: Número de intervalos de clase Muestral 𝑺 𝑆 = ∑ (𝑥 − 𝑥) 𝑁 − 1 = 𝑆 𝑥 : i-ésimo dato 𝑥: Media aritmética de los datos 𝑁: Número de datos 𝑆 = ∑ 𝑓 (𝑚 − 𝑥) 𝑁 − 1 = 𝑆 𝑚 : i-ésima marca de clase 𝑥: Media aritmética de los datos 𝑓 : Frecuencia de clase del i-ésimo intervalo de clase 𝑁: Número de datos 𝑘: Número de intervalos de clase Coeficiente de variabildad 𝑪𝑽 Para una muestra: 𝐶𝑉 = 𝑆 𝑥 100% 𝑆: Desviación Estándar de la muestra 𝑥: Media Aritmética de la muestra Para una población: 𝐶𝑉 = 𝜎 𝜇 100% 𝜎: Desviación Estándar de la población 𝜇: Media Aritmética de la población
- 5. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada MEDIDAS DE POSICIÓN Cálculo de Percentiles para datos no agrupados:
- 6. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada Cálculo de percentiles para datos agrupados: k-ésimo Percentil 𝑷𝒌 Para datos agrupados: 𝑃 = 𝐿 + 𝑘[𝑁/100] − 𝐹 𝑓 𝑇 𝐿 : Límite real inferior de la clase que contiene al k-ésimo percentil 𝑘: Número de percentil a determinar 𝑁: Número de datos 𝐹 : Frecuencia acumulada de la clase que antecede a la clase del k-ésimo percentil 𝑓 : Frecuencia absoluta de la clase donde se ubica el k-ésimo percentil 𝑇: Ancho real del intervalo de la clase del k-ésimo percentil Nota: Para determinar el lugar donde se ubica el percentil k, se usa la regla 𝑁. Estadísticos que usan a los cuartiles y percentiles Rango intercuartilar (RIC) 𝑅𝐼𝐶 = 𝑄 − 𝑄 𝑄 : Primer cuartil 𝑄 : Tercer cuartil Rango semiintercuartilar Rango semiintercuartilar = 𝑄 − 𝑄 2 𝑄 : Primer cuartil 𝑄 : Tercer cuartil Cuartil medio Cuartil medio = 𝑄 + 𝑄 2 𝑄 : Primer cuartil 𝑄 : Tercer cuartil Rango de percentiles 10 a 90 Rango de percentiles 10 a 90 = 𝑃 − 𝑃 𝑃 : Percentil 10 𝑃 : Percentil 90
- 7. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada MEDIDAS DE SESGO (ASIMETRÍA) Coeficiente de Sesgo 𝑪𝑺 Para datos no agrupados: 𝐶𝑆 = 𝑁 (𝑁 − 1)(𝑁 − 2) 𝑥 − 𝑥 𝑆 𝑁: Número de datos en la muestra 𝑥 : i-ésimo dato 𝑥: Media Aritmética de la muestra 𝑆: Desviación estándar de la muestra Para datos agrupados: 𝐶𝑆 = 1 𝑆 ∑ 𝑓 (𝑚 − 𝑥) 𝑁 𝑁: Número de datos en la muestra 𝑚 : i-ésima marca de clase 𝑓 : Frecuencia de la i-ésima clase 𝑥: Media Aritmética de la muestra 𝑆: Desviación estándar de la muestra 𝑘: Número de intervalos de clase Valor del CS y sesgo de los datos 𝑪𝑺 = 𝟎 Sesgo: La distribución de los datos es simétrica. Nota: La media, mediana y moda son iguales. Gráfica típica: Distribución simétrica 𝑪𝑺 > 𝟎 Sesgo: La distribución de los datos presenta sesgo a la derecha (o sesgo positivo). Nota: La media y la mediana se localizan a la derecha de la moda. Gráfica típica: Sesgo a la derecha 𝑪𝑺 < 𝟎 Sesgo: La distribución de los datos presenta sesgo a la izquierda (o sesgo negativo). Nota: La media y la mediana se localizan a la izquierda de la moda. Gráfica típica: Sesgo a la izquierda
- 8. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada MEDIDAS DE CURTOSIS (AFILAMIENTO) Coeficiente de Curtosis 𝑪𝑪 Para datos no agrupados: 𝐶𝐶 = 𝑁(𝑁 + 1) (𝑁 − 1)(𝑁 − 2)(𝑁 − 3) 𝑥 − 𝑥 𝑆 − 3(𝑁 − 1) (𝑁 − 2)(𝑁 − 3) 𝑁: Número de datos en la muestra. 𝑥 : i-ésimo dato. 𝑥: Media Aritmética de la muestra. 𝑆: Desviación estándar de la muestra. Para datos agrupados: 𝐶𝐶 = 1 𝑆 ∑ 𝑓 (𝑚 − 𝑥) 𝑁 𝑁: Número de datos en la muestra. 𝑚 : i-ésima marca de clase. 𝑓 : Frecuencia de la i-ésima clase. 𝑥: Media Aritmética de la muestra. 𝑆: Desviación estándar de la muestra. 𝑘: Número de intervalos de clase. Valor del CC y sesgo de los datos 𝑪𝑪 = 𝟑 Curtosis: La distribución de los datos es simétrica en forma de una curva normal estándar. Gráfica típica: Curva Mesocúrtica 𝑪𝑪 > 𝟑 Curtosis: La distribución de los datos es simétrica con un pico mayor que en el caso de la curva normal estándar. Gráfica típica: Curva Leptocúrtica 𝑪𝑪 < 𝟑 Curtosis: La distribución de los datos es simétrica con un pico menor que en el caso de la curva normal estándar. Gráfica típica: Curva Platocúrtica
- 9. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada MOMENTOS Momentos r-ésimo momento de la variable aleatoria X con respecto a cero: 𝑿𝒓 Si X1, X2, …, XN son N valores que toma la variable aleatoria X, entonces el r-ésimo momento con respecto a cero se define por el número: 𝑋 = ∑ 𝑋 𝑁 = 𝑋 + 𝑋 +. . . +𝑋 𝑁 Nota: Observa que el primer momento de X es igual a la media aritmética de X. r-ésimo momento de la variable aleatoria X con respecto a la media aritmética: 𝒎𝒓 Si X1, X2, …, XN son N valores que toma la variable aleatoria X, entonces el r-ésimo momento con respecto a la media aritmética se define por el número: 𝑚 = ∑ 𝑋 − 𝑋 𝑁 = 𝑋 − 𝑋 + 𝑋 − 𝑋 +. . . + 𝑋 − 𝑋 𝑁 Nota: Observa que el segundo momento de X con respecto a la media aritmética de X, es igual a la varianza de X. r-ésimo momento de la variable aleatoria X con respecto a cualquier origen A: 𝒎𝒓 Si X1, X2, …, XN son N valores que toma la variable aleatoria X, entonces el r-ésimo momento con respecto a la cualquier origen A se define por el número: 𝑚 = ∑ (𝑋 − 𝐴) 𝑁 X
- 10. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada ESTADÍSTICA BIVARIADA (DOS VARIABLES ALEATORIAS) Correlación lineal Coeficiente de correlación producto - momento de Pearson 𝒓 Datos muestrales: 𝑟 = 𝑛 ∑ 𝑥𝑦 − (∑ 𝑥)(∑ 𝑦) 𝑛(∑ 𝑥 ) − (∑ 𝑥) 𝑛(∑ 𝑦 ) − (∑ 𝑦) 𝑛: Número de pares ordenados a considerar. ∑ 𝑥, ∑ 𝑦: Suma de todos los valores x y suma de todos los valores y respectivamente. ∑ 𝑥 , ∑ 𝑦 : Suma de los cuadrados de cada x y y respectivamente. ∑ 𝑥𝑦: Suma de todos productos de cada x con su correspondiente y respectivamente. Coeficiente de correlación producto - momento de Pearson 𝝆 Datos poblacionales: 𝜌 = 𝑛 ∑ 𝑥𝑦 − (∑ 𝑥)(∑ 𝑦) 𝑛(∑ 𝑥 ) − (∑ 𝑥) 𝑛(∑ 𝑦 ) − (∑ 𝑦) 𝑛: Número de pares ordenados a considerar. ∑ 𝑥, ∑ 𝑦: Suma de todos los valores x y suma de todos los valores y respectivamente. ∑ 𝑥 , ∑ 𝑦 : Suma de los cuadrados de cada x y y respectivamente. ∑ 𝑥𝑦: Suma de todos productos de cada x con su correspondiente y respectivamente. Propiedades del Coeficiente de Correlación Lineal de Pearson • El Coeficiente de Correlación Lineal de Pearson es un número real que toma valores en el intervalo [-1, 1]. 1 • El Coeficiente de Correlación Lineal de Pearson es positivo si y aumenta cuando x aumenta. • El Coeficiente de Correlación Lineal de Pearson es negativo si y disminuye cuando x aumenta. 2 • Entre más cercano se encuentre el Coeficiente de Correlación Lineal de Pearson a -1 o 1, la relación es más fuerte entre las variables consideradas. • Si el Coeficiente de Correlación Lineal de Pearson es cercano a 0, entonces la relación entre las variables es más débil. 3 • El Coeficiente de Correlación Lineal de Pearson es útil sólo en el caso que las variables presenten correlación lineal. 4
- 11. FORMULARIO Alfabeto Griego y Símbolos Matemáticos GERARDO IGNACIO BONILLA ALFONSO Lic. En Mat. con EME. y Magíster(c) en Estadística Aplicada Regresión Lineal Recta de regresión (o de mínimos cuadrados, o de mejor ajuste) Modelo: 𝑦 = 𝛽 𝑥 + 𝛽 𝛽 = 𝑛 ∑ 𝑥𝑦 − (∑ 𝑥)(∑ 𝑦) 𝑛(∑ 𝑥 ) − (∑ 𝑥) 𝛽 = (∑ 𝑦)(∑ 𝑥 ) − (∑ 𝑥)(∑ 𝑥𝑦) 𝑛(∑ 𝑥 ) − (∑ 𝑥) (𝛽 es la Pendiente de la recta de regresión) (𝛽 se denomina Intercepto, y corresponde a la Ordenada al origen de la recta de regresión, o lo que es lo mismo, la intercepción de la recta con el eje y) Error estándar de estimación de Y sobre X 𝑆 , 𝑆 , = ∑ 𝑦 − 𝛽 ∑ 𝑦 − 𝛽 ∑ 𝑥𝑦 𝑁 − 2