Descargar para leer sin conexión

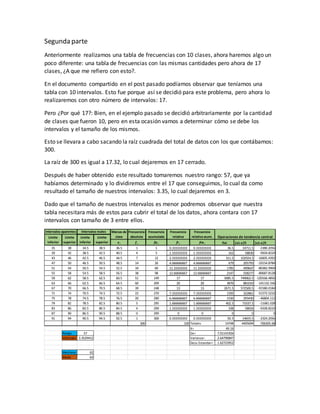
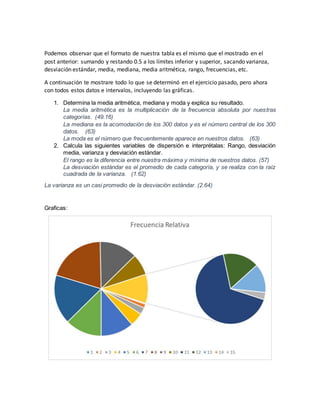
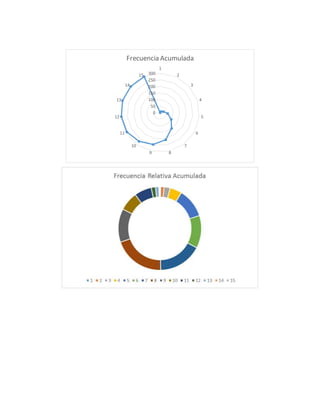

Este documento describe cómo crear una tabla de frecuencias con 17 intervalos en lugar de 10 para los mismos 300 datos. Explica que la raíz cuadrada de 300 datos es 17, por lo que habrá 17 intervalos. El rango de los datos (57) se divide entre 17 para obtener un tamaño de intervalo de 3. Luego calcula medidas de tendencia central como la media, mediana y moda de los datos agrupados en la nueva tabla de 17 intervalos.




























































































